
In a recent project involving an event-sourced CQRS system, we decided to do some things that seem somewhat unusual compared to solutions mostly talked about. However, they let us achieve some nice properties that would be hard (if possible at all) otherwise.
Event Store as Regular Table
We decided to implement the event store as a regular table in an RDBMS. We used PostgreSQL, but there is little PostgreSQL-specific here. We know this database is very reliable, powerful and simply mature. On top of that, single-node ACID transactions provide some really nice benefits.
The table ended up with the following fields:
event_id(int) – primary key coming from a global sequencestream_id(UUID) – ID of an event stream, typically a DDD aggregateseq_no(int) – sequence number in history of a particular streamtransaction_time(timestamp) – transaction start time, the same for all events committed in one transactioncorrelation_id(UUID)payload(JSON)
Not all of them are mandatory for an event store, but there is one important and uncommon difference: event_id – globally, sequentially increasing number. We’ll get to that in a moment.
Can You Do It?
If you go for an event store in a regular DB table, getting a global event ID like this is extremely cheap. Databases are really efficient generating, storing, indexing etc. such columns. The only actual problem is whether you can afford using a DB table for it in the first place.
The limits for an append-only relational table are much higher than most applications will ever need. Postgres can easily handle thousands (or tens of thousands) of writes per second.
Using a relational database certainly adds overhead and it’s not something I’d recommend if you were building the next Amazon. But chances are you aren’t, and so you may be able to afford the luxury of using simpler technology.
Benefits of Global, Sequential Event ID
Now that we have this peculiar event ID, what can we do with it?
Let’s have a look at the read interface of our event store:
public interface EventStoreReader { List<Event> getEventsForStream(UUID streamId, long afterSequence, int limit); List<Event> getEventsForAllStreams(long afterEventId, int limit); Optional<Long> getLastEventId(); }
The first method is pretty obvious and something you can find everywhere. We only use it to restore a single stream (aggregate) from the event store for handling a new command.
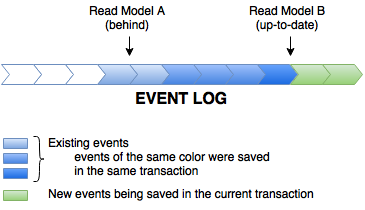
The other two are using the event ID, returning a batch of events after a particular event, and ID of the last event. They are the base of our read models (projections).

Read models are implemented by polling (with hints) the event store. They remember the ID of the last processed event. Every once in a while (or when awoken by a notification from the event store), they read the next batch of events from the store and process them in sequence, in a single thread.
This kind of linear, single-threaded processing is probably as simple as it can get, but it obviously has limited scalability. If you get 600 events per minute, it means on average you cannot be slower than 100 ms per event, no matter what. In reality you also need to consider overhead and leave some headroom, so it needs to be faster than that.
It can be addressed with sharding or parallelizing writes in the read model, but for the moment we did not find it necessary. Having multiple independent, specialized models running in parallel certainly helps with that.
Comparing the last-processed event ID for a projection to the current global maximum, you can immediately tell how much behind the projection is. It’s the logical equivalent of queue size.
The global sequence can also be used to mitigate the downsides of eventual consistency (or staleness).
Executing a command could return the ID of the last written event. Then a query can use this ID, requesting: “I’m fine waiting 5 seconds, but don’t give me the result if your data is older than this ID”. Most of the time it’s a matter of mere milliseconds. For that price, when a user makes a change, she immediately sees the results. And it’s the actual data coming from the server, not simulation achieved by duplicating domain logic in the user interface!
It’s also useful on the domain side. We have some application and domain services that query some domain-specific projections (e.g. for unique checks). If you know that the last event in the event store is X, you can just wait until the projection catches up to that point before making further progress on the command. That’s all it takes to address many problems typically solved with a saga.
Last but not least, since all events are ordered, the projection is always consistent. It may be behind by a few seconds, or a few days, but it’s never inconsistent. It’s simply impossible to run into issues like having one stream processed until Monday, but another until Thursday. If something had happened before a particular event occurred, the same order is always maintained in the view model.
It makes the code and the state of the system a lot easier to write, maintain, and reason about.
Scalability and Complexity Revisited
There is a tendency to use complex, high-scalability technology regardless of the actual customer requirements and realistic scale. Such tools have their place, but they’re not obvious winners, no golden hammers solving all problems. Moreover, they are really expensive, if you consider the complexity of development and operations, and their limits.
Sometimes a simpler tool will solve the problem well. Not only do you save on development and ops, but also gain access to some really powerful tools that are impossible at high scale. Including global counters, linearizability and ACID transactions.
SQL databases are really fast and come with many useful tools in the box. Linear processing aligns well with hardware limitations, and its limits in general (beyond SQL) are at least in the order of millions of transactions per second for a single thread.
There are many good reasons to choose boring technology. If you innovate (and you should), be careful with why you actually do it, and don’t innovate in all areas at the same time.
One thought on “Achieving Consistency in CQRS with Linear Event Store”
Comments are closed.