Here at Oasis Digital and its sister company (Expium), we offer training and services concentrated around various languages and frameworks:
Angular
TypeScript
Node
The web platform in general
JIRA, Confluence, and other Atlassian products (Expium is an Atlassian Solutions Partner)
There are many reason – technical, history, intentional, and accidental – around how we ended up with this set of technologies as our 2017 training and consulting focus.
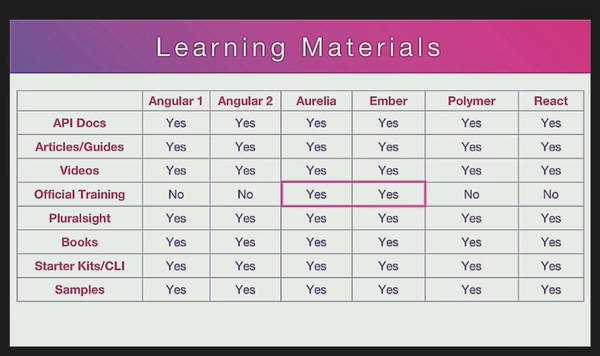
I was reminded of one key factor today while watching a video from last year of a talk by Rob Eisenberg. Rob is exceptionally sharp, and seems to have a good sense of taste in designing frameworks for developer satisfaction. But I found myself in disagreement over his thoughts around web framework adoption. Rob argues that frameworks like his (Aurelia) are stronger, better choices to build on than frameworks like Angular and React, because first-party training and support services are available for Aurelia from the makers of Aurelia. This initially seems like a compelling pitch, I can see how it would woo some decision-makers. Here is a snippet of one of the slides along these lines, pointing out first party training as an advantage:
But I think ultimately this works out much less well than Rob describes. Why? Because this first party set of training and consulting offerings leave less space for a thriving commercial ecosystem to develop around a framework.
Let’s look at Angular for example. Here at Oasis Digital, we aim to be a leader among many firms around the world, who provide training, consulting, etc. for Angular. Our customers are quite happy with the availability of these services from many different companies; it reduces their risk and means they can shop around for the best fit. Moreover, because Angular has created opportunities for companies like Oasis Digital, it has facilitated a growing commercial ecosystem revolving around the framework. Much the same applies, for example, to React and Vue.js. This is a virtuous cycle. The non-service-offering core team leaves room for others to provide services, which in turn makes it easier and safer for customers to adopt the framework.
(A second example at Oasis Digital’s sister company Expium: Expium focuses entirely on the Atlassian product suite. While Atlassian offers online video training options, Expium’s offerings include things like live human training that don’t compete directly with Atlassian’s offerings. Atlassian enjoys a thriving commercial ecosystem.)
Of course it would be possible for companies like us to offer training and consulting focused on Aurelia. But we don’t want to do that; we like the people responsible for the framework. If we offered services for Aurelia, we would have an inherently competitive relationship with the company behind Aurelia, vying for the same customer opportunities.
This situation applies to various other frameworks and other technical specialties that we could choose to focus on; with so many choices, it inevitably feels wiser to choose those where we can be allied with the core teams rather than in competition with them.
I believe that overall, this is quite important in understanding why some frameworks gain enormous momentum and others do not. Creating this kind opportunity for a commercial ecosystem is an immense competitive advantage to those companies who can offer a framework without needing to build a business directly around it – like Google and Angular.
Sometimes your Angular application needs to be a little bit different depending on the environment. Maybe your local development build has some API services stubbed out. Or you have two production destinations with a little bit different behavior. Or you have some other build-time configuration or feature toggles.
The differences can be on any level: services, components, suites of ngrx/effects, or entire modules.
For example, it could look like this:
The dependency injection and module mechanism in Angular is pretty basic, and it does not seem to offer much to answer such use cases. If you want to use ahead-of-time (AOT) compilation (and you should!), you can’t just put random functions in module definition. I found a solution for doing it one service at a time, but it’s pretty ugly and not flexible enough. The problem does not at all seem uncommon to me, though, so I wanted to describe a nice little trick to work around this.
Sample app
Let’s study this on a sample app. To keep things interesting, let’s make a realistic simulator of various organization hierarchies.
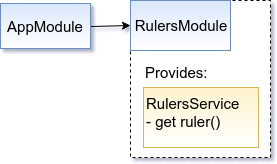
We’ll need a component to tell us who rules the “organization”:
app.component.html
<h1>Who owns the place?</h1>
{{(ruler | async).name}}!
exportabstractclass RulersService {
abstract get ruler(): Observable<Ruler>;
}
On a picture it could look like this:
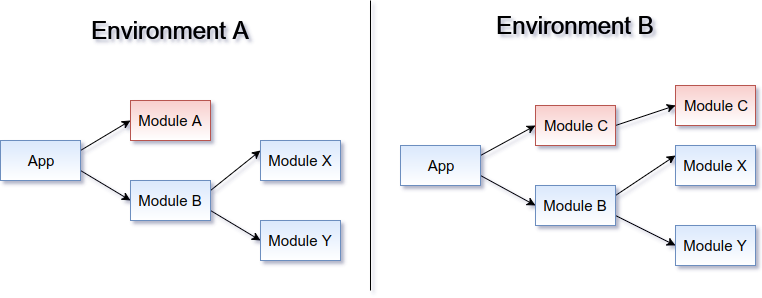
Now, let’s say we have two environments:
Playground, where little Steve would really like to own the place… except that he can only do that when the local bully is not around, and that’s only when he’s eating. To determine the ruler we need to ask the Bully’s mother about his status. So it goes.
Wild West, where the rules are much simpler in comparison: It’s sheriff who runs the show, period.
In other words, we need something like this:
So, how to achieve that?
Solution
The solution is actually pretty straightforward. All it takes is a little abuse (?) of Angular CLI environments. Long story short, this mechanism provides different environment file to the compiler based on a compile-time flag.
If you check the documentation or pretty much any existing examples, the environments are typically used to provide different configuration. Just a single object with a bunch of properties. You might be tempted to use it in some functions on module definition, but it’s not probably not going to work with AOT. Oops.
However, at the end of the day it’s just a simple file substitution. You can put whatever you like in the file, and as long as it compiles everything is going to be OK. Classes. Exports from other files. Anything.
In our case, the AppModule can import the RulersModule from the environment. It doesn’t care much what the module actually contains.
The environments would export it from the relevant “package”. They could have the classes inline, but I prefer to keep them in separate files closer to the application.
environment.playground.ts
exportconst environment = {
production: true
};
export { PlaygroundModule as RulersModule } from '../app/rulers/playground/playground.module';
environment.wild-west.ts
exportconst environment = {
production: true
};
export { WildWestModule as RulersModule } from '../app/rulers/wild-west/wild-west.module';
The final trick that makes these work is that there is an abstract class/interface for the RulersService, and AppComponent (or other services, if we had them) only depends on that. Actually, this pattern has been around for a while. This is the old good programming to interfaces.
The same goes for the RulersModule: In a sense it’s abstract too, AppModule doesn’t know or care what concrete class it is. As long as the symbol with the same name exists during compilation.
This sample demonstrates it on the module level, but you can use the same trick for any TypeScript code, be it a component, a service, etc.
I am not sure if such use of environments is ingenious, or insane and abusive. I have not seen this anywhere. However, it does solve a real problem that does not seem to have a solution in the Angular toolbox (and it’s not particularly toxic).
The current state of server-side rendering (so-called “universal”) for Angular is somewhat in flux in mid-2017. There had been an early Angular Universal effort by an outside group, which has now been absorbed into the core Angular team at Google. They are working toward a new release (to become part of an Angular release) which integrates it tightly is a fully supported first-class piece of the Angular tool suite.
Very eager developers, it is possible to use some of these tools now; but it should become easy and mainstream in the coming months. The primary use cases are:
1) SEO
Site/applications which have publicly exposed pages for which search engine optimization is needed, prefer to statically render (and serve) the key SEO pages. Historically this was vital, because search engines did not execute JavaScript on the pages being indexed. However, for at least the last several years, Google and its other top-tier search engine competitors do execute JavaScript on a page, so the SEO use case is not as important as it used to be. Many still prefer to statically render pages for maximum SEO, nonetheless.
2) Progressive Web Applications
This is the current leading edge of aggressively performance web applications for mobile devices. The idea is to statically load the outer “shell” of an application with some initial static content displayed, then replace that initial content with fully dynamic content a few seconds later. That initial load involves the smallest feasible amount of HTML, CSS, JavaScript.
PWA is a compelling idea, but there are practicalities to its appeal:
* PWA is mostly relevant on mobile devices. An optimized Angular application will load very quickly on a desktop machine regardless.
* PWA is most important on down-level devices and networks. It doesn’t make as much difference on those of us sitting in well-networked places on LTE with current generation smart phones – or on fast corporate networks.
* PWA matters most on the first load of a page/application. After that, many of the assets will be cached so the real content will load very shortly after the progressive pre-render.
The coming default
We believe the tooling will eventually work so nicely, that static pre-rendering and PWA become straightforward, or even become the default path for new applications. But keep in mind the practicalities above – for many use cases, pre-rendering and PWA make sense to adopt only when the tooling makes it very straightforward. Developer efforts between now and then probably pay off more if directed toward application functionality and polish.
From the summer 2016 production release of Angular, most users have treated AOT as a future curiosity. As of late fall 2016 though, many (particularly those working on larger applications) have been much more eager and interested to use AOT. Here at Oasis Digital, we have recently updated our Angular 2+ curriculum to ensure the numerous code examples used in class are AOT-ready.
Although most of our production Angular 2+ work uses the Google-sponsored Angular CLI (which was excellent AOT support), we’ve also been working with various alternative tooling stacks. Some of our customers integrate their Angular applications with broader build processes and are looking for more fine-grained control than they get with the official CLI.
See the README in the project for a lengthy explanation of how it works and why these tools were chosen. It was mostly straightforward to make this work; the configuration is quite simple. However, as of the beginning of March 2017 there is an important Rollup plug-in which does not yet have the ability to consume the new Angular ES2016 FESM bundles. To work around that, I published a (hopefully temporary) fork of that plug-in, “@oasisdigital/rollup-plugin-node-resolve“.
Another variation
The boring, excellent, proven, and still frequently updated Google Closure Compiler can often produce better results than newer, hip tools. Therefore the following variation/branch:
…replaces a couple of the tools with Closure Compiler. It uses only:
AOT (ngc)
Rollup
Closure Compiler
With fewer tools, it produces a smaller results. The configuration is slightly more complex (mostly because the Closure Compiler JavaScript port is not quite the same as the Java edition yet), but is still quite manageable.
I have not yet compared this with an even shorter stack (using Closure Compiler for the tree shaking as well), as there are examples around already doing that; but I expect an upcoming enhancement to Closure Compiler will add the “es2015” package field support needed for the ES2015 FESM bundles, once that is in place I am curious as to whether Rollup or Closure (both very respected as excellent tree shaking tools) will produce tighter results.
Why this matters
For projects deployed on an intranet, it’s possible that none of this matters. A very large internal enterprise project might ship a total of 6 MB of compressed JavaScript (hopefully divided across various bundles littered on demand) with the default tooling, or 5 MB with tweaked tooling. That won’t matter across a gigabit network with people mostly using an application frequently (and therefore with the JavaScript mostly in cache.
But not all projects are huge or internal. Angular is also well-suited for medium-to-large projects deployed on the open Internet to a huge number of sporadic users. For these users, who might be on slow connections, saving bytes counts. Faster load times translate to more user engagement. Better production bundling expands the reach of Angular two more kinds of projects.
The above is not even counting mobile; as Angular mobile application development continues to increase, the tightest possible production bundles will matter more and more.
As of December 2016, what tooling should be used for a new Angular 2 project?
This is a question we get from customers and students frequently. Here is our current best advice, which will change over time. The context is critical: projects that may start small but are likely to grow to significant, complex enterprise applications.
Here is the path we have been following and recommending. At Oasis Digital Digital we have had excellent results with Angular 2 (soon to be 4, and beyond).
Use the official Angular CLI, which is full of excellent ideas but is also still in development, working toward a solid “V1”. As your project starts out simple, it is extremely easy to get up and running this way, and to get very good results. Highly recommended.
As your project grows in complexity, consuming and using CLI will need some ongoing attention from a team member on your project. A complex Angular project needs at a build guru, who should:
Tune into the Angular CLI community, become aware of what is going on with CLI
Choose an Angular CLI version wisely. For example, as of mid-December 2016, CLI Beta 21 is the right choice for most projects while the more current Beta 22 will land you among some current challenges around AOT compilation and third-party libraries.
With this awareness, when you encounter difficulties you will likely recognize what is going on, and be able to work around it quickly. This has been our experience, certainly; we have never had our progress delayed by more than a short time, by build issues. But if you don’t have this awareness, you risk a build issue derailing your project for days or more.
If your project becomes so complex that this strategy for using Angular CLI does not work, Eventually it may be necessary to set aside Angular CLI for a while, and instead adopt one of the Angular 2 “seed” projects. These projects typically ship with a surprising amount of complexity which will become part of your project, and to the extent you edit any of this complexity, upgrading becomes difficult. Therefore we recommend not starting with a seed, rather having it only as a fallback plan if your project reaches a point where it cannot proceed with CLI.
Here is a video of the talk “managing state and Angular 2 applications” from the October 2016 St. Louis Angular lunch. The post below has roughly the same ideas, but with much less detail, in text form.
Managing State in Angular 2 Applications
The 6 stages of Angular 2 state management
Here at Oasis Digital in our Angular Boot Camp classes we meet developers working on Angular 2 projects at lots of companies, in addition to the projects we work on ourselves. As a result, we have a sense of the challenges faced while working with Angular 2 at scale.
The “at scale” part is important; we focus on serious, scaled use of Angular 2 and other tools; generally people building small things don’t have budget to take classes or engage consulting assistance. So take everything we write with a “grain of salt”: we are writing and thinking and talking and working on large complex projects.
Over time and across multiple projects, we have gone through a progression of how to think about and implement state management in Angular 2 applications, and our advice to customers is generally about moving along these stages.
What is state?
From a computer science point of view, state is any data that can change. The source of the change can vary, and the presentation of the change can vary. Regardless of those things, state leads to complexity, and in particular desired or accidental interaction between aspects of state is often, ultimately the greatest source of either value or cost in a complex software system.
Be wary of arguments that something is “not part of the state”; it often ends up part of the state as after all. For example, any of these often turn out to be part of the state that must be managed:
URL / “route”
Error conditions
“Local” state
Partially entered data
Partially arrived data
Reference / lookup data
Stage 0: State per component
Some small, simple programs have little meaningful state. The most obvious and easy place to store state in Angular 2 applications is in the components which “own” the state. For example, a component which displays a list of contacts retrieved from the server might simply:
store that list of contacts in a field
loop over the contacts with NgFor for display
retrieve the contacts from an API using HTTP and subscribe.
In such simple cases, there is little to think about, and Angular change detection just works.
There are also slightly more complex programs in which the state can easily reside in a handful of independent components. If the components don’t interact in any way, even if each one has a small amount of state the overall state full complexity of the software remains very low.
We see very few programs “in the wild” that remain in this stage of simplicity.
Tip: Watch the video instead of just reading. The video has diagrams.
Stage 1: State in interacting components
Slightly more complex applications have some interaction between components. The most straightforward and obvious way to handle this interaction is to have each component “own” a portion of the overall application state. Then use events and bindings to push that state up and down and across the component hierarchy to other components which need to receive it.
This design starts straightforward, and continues to match what new developers are shown in the documentation, in the QuickStart, and so on. This stage of complexity is what we most often see developers begin to create as they learn Angular 2. Depending on the complexity of interactions, some applications can get quite far with this design.
Unfortunately, the complexity and difficulty can begin to increase depending on the details of the interactions of these various state full components. In particular, things get painful when you realize there are many copies of various aspects of the state of your systems spread throughout a component hierarchy – and you have lost track of exactly which component “owns” which aspect of the state.
With increasing fury at the keyboard, it is possible to keep the relevant parts of the state in sync with each other, sometimes resorting to awful hacks:
ngOnChanges methods which implement business logic, pushing state back and forth between components
Even worse, set timeouts and other means to notice data has changed in one place and needs to be copied another place
Begging or raging on StackOverflow for something like $scope.watch() from Angular 1
Still, it’s important not to be overly negative about this approach. For applications with only a little state complexity, it can work fine. Few of the applications we build that Oasis Digital remain in such a condition though.
Stage 2: State in one component at the top
In a quest to bring order to the chaos that occurs with different bits of state owned by different components spread across a hierarchy, a wise developer will study the Angular 2 documentation and learn the key organizing principle:
Bind data downward, emit change in events upward
To implement that, move state ownership upward through the component hierarchy, such that each piece of state is owned at a high enough level that it can be pushed down to any other components that need it. In extreme cases, some applications have essentially all of their state all the way in a top-level component.
This fixes the “sync” problem, and is very compatible with Angular. In particular, it enables many of angular’s key performance optimizations, it lets you specify change detection as OnPush.
However, with a more scale the problems appear:
Topmost or other high-level components and up looking a lot a bin of global variables
Extensive code throughout the component hierarchy, a “bucket brigade” carrying numerous events upward and numerous aspects of data downward.
As of October 2016 (with comments by core team members about a fix coming), the numerous event and data bindings are all completely untyped, outside the realm of where TypeScript can detect and assist with them.
We got quite far on applications with this approach. It can handle applications of modest complexity with no trouble at all, and it is very compatible with the Angular binding/event view of the world. Ultimately though, the problems noted above became unworkable and we have ceased using or recommending this approach.
Stage 3: State in services
In a project where the bucket brigade is out of control, developers will often switch to a common technique from Angular 1: put the primary representation of each aspect of the state of the software, in services which are then injected wherever they are needed.
To do this, you must set aside OnPush, and rely on Angular 2 change detection. That change detection is surprisingly efficient, so this compromise is not particularly problematic in many applications. Moreover, each state full service can be injected only and exactly into the components where that state is needed. The bucket brigade is gone, and instead the dependency structure of the source code maps to the use of state. The software becomes much easier to reason about.
Unfortunately, reacting to change in the state is still quite difficult with this approach. That can become obvious when the project starts using the following hacks:
Create a component which injects services and then binds data from those services using its template, into a function. Write code in that function to perform computation based on that joint state changing.
Create a component which injects services and then binds the data from those services into another component underneath it; inside that lower component, use OnPush for efficiency and then write business logic in ngOnChanges to be notified and take action when the data has changed.
Why are these hacks? We consider them hacks because they abuse Angular capabilities primarily intended for manipulating the view/UI of an application, to instead call business logic. If you find yourself writing “business logic” in ngOnChanges, things have gone horribly awry.
Even with the hacks in place, with a tiny bit more complexity, getting programmatic control over the changes in state of the system becomes very difficult and tangled.
Stage 4: State in Observables (in services)
Fortunately, while using Angular 2 you already have a tool in your toolbox very well suited for reacting to change: Reactive eXtensions for JavaScript, RxJS. To take advantage of it for managing state:
Remove/disallow state in components
Remove/disallow (most) state in service class fields
Put the state inside Observables (sometimes Subjects or BehaviourSubjects actually) in those service classes instead
Inject the services to whichever components need them
Use the async pipe in the components to get the data from the observables into the view
Write code in the services which uses the RxJS API to respond to and propagate changes to state stored in these Observables
This general pattern has already been reinvented numerous times in the Angular 2 world. It has many advantages:
Easily bring state to where it is needed
Single copy of each piece of state
Clear obvious place to write reactive business logic
Extensive selection of RxJS operators to manipulate the state
Efficient use of Angular 2 view binding with OnPush
An observable centric, application-specific state management mechanism can work very well. At this stage really the only downsides are:
Each team or application reinvents a way to do this, and therefore is not benefiting from any common libraries or tooling.
A large complex state spread across many observables becomes unwieldy to the extent the front aspects of that state interact.
Also at this stage, developers generally have the feeling that they should have seen this problem before. And in fact many developers have, and already worked on solutions:
Stage 5: Choose and Use a State Library
We consider this the stage that any nearly every mature Angular applications to reach. Choose and use a proven library or approach for state management.
State library options
The two libraries that come to mind most often are those which implement the Elm architecture / Redux pattern with Angular integration.
Regardless of which you choose, you obtain generally the same benefits:
Your ideas and code are useful across Angular and other, non-Angular platforms
Write mostly unencumbered TypeScript code, rather than code which only makes sense and executes meaningfully with the help of a library
Excellent control of change
Excellent test-ability – in most cases the essential logic of your application can be tested apart from Angular itself
Tooling support, for things like “time travel debugging”
Community – when you have a problem, you’re likely not the first to have this problem, and you will likely find hopeful and useful discussion online
Beyond the libraries
Alternatively, you might find that the Elm/Redux approach is not ideal for your needs. Here are some other directions to consider.
Over in the React world, MobX is receiving substantial attention as a less tedious way to obtain most of the same benefits as Redux. Perhaps it will find its way here to Angular.
If you store your state in Firebase, Firebase itself will handle propagating the state around your application (as well as between numerous devices). In some it can serve most of the needs for state management.
Andre Staltz, author of CycleJS, argues that Observables-all-the-way-through is compelling. Even if you never use his CycleJS library, watch a few talks and take it for a spin.
For some applications we are loading data with GraphQL; although are currently doing so in the context of the state management systems, the opportunity is out there for certain aspects of local state management to be abstracted away. The future around this is still unfolding, but it seems inevitable that this new direction of abstraction will strongly affect application state management in the future.
How big before this matters?
Now you might think from this description but I’m talking only about huge complex enterprise apps. Not true. Even fairly small applications, can end up having surprising difficulty in state management. We have a piece of training curriculum which attempts to manage state responsibly in a tiny application whose code can be fully reviewed in just a few minutes. It ends up at stage 4 (in the list above) without really trying.
You might also think, “but I’m not talking about application state, I’m just talking about whether a checkbox is checked on a form”. This sort of thing initially seems like it can be omitted from a broad notion of application state, and that is true, until you want to implement certain features, and then it is not true anymore.
Most broadly, if you are not working on an application complex enough to care about state management, why are you using a library as large, complex, feature full, and powerful as Angular?
In our work at Oasis Digital, we have concluded that for most projects, the right answer is to proceed directly to full powered state management.
An alternative view
Our point of view here may be contentious, and is certainly not the only point of view among experienced Angular developers. Most notably, Ward Bell, and all-around experienced Angular guru and key author of the Angular official documentation, argues that only a small minority of Angular applications warrant a complex state management approach.
One wish for Angular 3: Stateless components
Currently, components and Angular 2 are classes, classes are a deeply OO concept which mix behavior and state. For some uses, this is excellent. For others, and for some of the architectures described here, the tight coupling between stateful components and the Angular 2 view mechanism is not so beneficial.
A second wish: Higher-order components
If we had stateless components, that gets us halfway to tooling support for rigorous separation of state and view. How do we get the other half of the way? We get there using higher order components, you could think of these as components that emit components, meta-components, functions that emit components, something like that.
The point being that sometimes you want to specify all the gory details of the component, and the current Angular decorator mechanism is perfect for that. Other times you want to programmatically say, “please wrap my component with another component defined by the following function”. There is not currently a way to do that. There are technical challenges with it, around how Angular compiles components statically.
However, I have great confidence that the core Angular team will eventually (Angular 3/4/5/6/N) will grow something akin to higher order components.
Summary
If you are working on nontrivial Angular applications, as soon as you hit state management difficulty start learning about sophisticated, powerful state management approaches and tools ASAP.
Major congratulations to the Angular team, who just shipped version 2.0.0. In development somewhere approaching two years, it is an extraordinarily ambitious effort and the result is very much ready for prime time.
It also seems like a good time for a snapshot of what we at Oasis Digital have been doing with Angular 2, prior to the release:
Created curriculum, in some cases before there was official documentation available.
Launched customer projects, both “proof of concept” and headed for production.
These are all things we will continue to do, and it feels very good, as of September 2016, to be doing them for a product which has shipped in production-blessed form.
Sorry, the title is actually a lie. It takes 2 minutes of human work to get up and running, but you have to wait about 10 minutes in the middle for node modules to install. You can wander away during that long process, so we will politely pretend it really only takes 2 minutes.
Watch it happen
Explanation
For our Angular Boot Camp, we have been assisting lots of students as they configure their computer to work on Angular 2 projects. Recently we have been including the nascent Angular 2 CLI in this process. Either way though, installing the needed tools is fast and easy if you have a generic, off-the-shelf computer, with an extremely fast CPU and disk on an extremely fast network. It is less fast and easy if you are running on something like an older computer, with various old versions of software installed, and it can be quite painful on a locked down corporate computer.
To skip past this and start teaching our students Angular 2 with its CLI as quickly as possible, we sometimes suggest they try out Cloud 9. C9 is a web-based IDE; we are not affiliated with it in any way, other than as fans and customers. While we prefer more typical desktop IDEs (like VSCode and WebStorm) for most use, Cloud 9 is very useful for sharing a development session across the group of developers around the room or around the world. So it is a great tool to have in the toolbox.
To get up and running though, requires a few gymnastics. We have bundled up these gymnastics to a script which you can “source” into a Cloud 9 terminal window. See the video for details; here is the line of text you will need:
As with any such command, there are security concerns. I don’t advocate running commands like this on your local computer, but if you’re running it in a freshly created throwaway Cloud 9 instance, security is not such a concern.
Downsides
There is currently one major downside of Cloud 9 for Angular 2 development: code completion, formatting, and other important IDE features are not yet available for Typescript in Cloud 9. The syntax highlighting works well but the other features have not yet arrived.
There are numerous choices for tooling in a TypeScript Angular 2 project. This list is no doubt incomplete:
SystemJS with JSPM
SystemJS without JSPM
Webpack
Angular-CLI (which uses System and Broccoli and other things behind the scenes)
(Warning – this content has been made obsolete by progress in Angular 2 and related tooling.)
At Oasis Digital, we have worked with all of these variations, and experienced trouble at least with all of them but have been around long enough to have trouble with. There is no clear winner yet, there are only trade-offs.
Speed matters. Specifically, speed of the development cycle, of how long it takes to compile/recompile an application and reload it in the browser during development. (I’m less concerned with the speed of a “production build” because those happen much less often and usually without a human actively waiting.)
As of May 2016 (these things change rapidly) we have found the following yields the very fastest results for the development cycle:
Bundle libraries using JSPM/System-Bundler or WebPack, or use bundles shipped by the Angular 2 team.
Set up tsconfig to use “module”: “system” and “outFile”: “somebundlenamehere.js”. TypeScript both compiles your code, and produces a single-file bundle of the results. This is much faster than having typescript emit numerous files and then bundling them with another tool.
Run tsc in your IDE; don’t bother to “watch” from the command line or by other means – better for compile errors to land in the IDE. There is no benefit to simultaneously compiling in your IDE and in a concurrent “watch” – omitting that (for example, by moving away from Webpack) roughly cuts in half the total CPU effort spent on each development cycle.
To demonstrate how little work is typically needed to set this up, see the following tiny “fork” of the angular.io “quickstart”. This single commit shows the slightly less configuration needed with the “module”: “system” approach.
Of course, there is no benefit to this change in the quickstart application – the tutorial adds only a handful of components. But we have confirmed the performance lead with other teams developing on Angular 2 “at scale”. This approach is, as of May 2016, the fastest compile-reload cycle for large Angular 2 applications.
It might not last long; there are many efforts underway, including the official angular-cli, to build better development tooling. Moreover, Hot Module Reloading might make speed up the development cycle enough that the clean-reload time isn’t important.
As I write this in April 2016, Angular 2 is in beta (with a recent comment from Google about a release candidate coming soon), and while it is still early days for production Angular 2 use, we already know of a number of projects (including here at Oasis Digital) heading rapidly in that direction.
Looking around the Internet, listening to the podcasts, reading the blogs, watching the GitHub repositories, we have seen a surprising early emergence of an architectural preference with Angular 2. Here is our expression of this preference, I’m sure a group of thought leaders could gather and each would have a different take on it of course.
In a complex Angular 2 SPA:
Avoid the “bucket brigade” of data binding business domain data one component at a time across an application component hierarchy. The new syntax makes each step of the bucket brigade tidy, but still ultimately error-prone and tedious. One binding is good, a series of bindings one to the next is not.
Avoid unmanaged state floating in a bunch of stateful services (classes) – now that it is easy and fast to create these as plain classes with Angular 2, it is also easier to create a complex enough system that unmanaged state leads quickly to slow, error-prone, complex development.
Use RxJS heavily. There is some dispute around the web as to whether RxJS is the most ideal implementation of reactivity, but it is emerging as the most popular, and the one most similar to an upcoming likely standardized API.
Adopt the Redux / Elm architecture, coalescing all application state to a central (but hopefully well-modularized) data store, mutated only by the processing of actions using reducers.
The early leader as the “glue” to do the above in Angular 2 is ngrx/store.
Test essential logic at that central state.
If you happen to be using a Node backend, it it very easy to share data structure definitions and UI-free application logic between client-side and server-side code. Do so as needed.
We have adopted this architecture where suitable, we see lots of activity around the web which indicates others are adopting something similar. This approach generally is likely to emerge as the dominant approach in complex Angular 2 development. Further, it appears to be part of a growing trend across a variety of SPA libraries/frameworks. Whether using Angular 2, AngularJS, React, Cycle, Vue, OmNext, etc., this idea of state separated from UI logic is compelling.
(Conveniently, here at Oasis Digital, we are deeply familiar with CQRS/ES, and this Elm/Redux architecture echoes quite strongly of that.)
What does this mean for Angular 2 development? I think most likely it means: the differences between Angular 2 and its competitors are growing less important. If you are managing state in a centralized, decoupled manner anyway, the choice of UI / view layer becomes more a matter of development preference than before. This is a tremendously positive development.
How should AngularJS 1.x be used, to make things easier (as easy as they can be…) if the time comes to port an application to Angular 2? This is a frequent topic of discussion at our Angular Boot Camp classes, which are still quite popular (in early 2016) for AngularJS 1.x even as Angular 2 grows close to release.
We often have students or private class managers ask that our class cover this topic, but they really don’t even need to ask. Over the last 6-9 months we have revamped our curriculum and approach to teaching AngularJS 1.x to pervasively answer aspects of this question. Here it is, in a more explicit summary:
Build your application mostly from components. If you are able to use 1.5 right now, go ahead and use the new .component() API extensively. If you are stuck on an older version, use component style directives. Regardless, mostly follow the component pattern, only reach for a standalone controller or template in rare cases.
The migration tools coming from the core team are about migrating from 1.5 forward, not about older versions; so if you have an application built on an 1.4, 1.3,, or even older, now is a good time to move past whatever is stopping you from upgrading to 1.5. There are numerous other benefits to upgrading also, each incremental version of AngularJS 1.x has improved performance and other areas.
Make your components mostly push data downward using data binding.
Make your components mostly push information about things that happened upward, mostly using “&” hooks (the closest thing in A1 to A2 events).
Mostly use the A1 features data binding, to avoid needing to write things like manual $watches. We have found at Oasis Digital that nearly every manual watch can be removed and replaced with data binding, letting AngularJS itself watch (and stop watching when appropriate) an expression instead.
Minimize or avoid the A1 scope event system; use it only in very unusual cases. There is nothing like it in A2, and even in A1 it is of limited utility with a component-centric approach. Those isolate scopes will stop events anyway. We typically use the scope event system only for things like talking to APIs which are exposed in that way (like route change notifications).
Consider TypeScript, today, even on AngularJS 1.x. Here at Oasis Digital, we have done this and been very pleased with the results. We have found and fixed numerous bugs with the help of the type system, which otherwise would have been fixed later and a greater expense and risk, with testing or with production failures.
An application built in this way (and following some other things that I have overlooked) is ready to walk the Google-sanctioned migration path, mentioned from conference stages by Google team members. First make old code look more like Angular 2 (ng-forward), then put Angular 2 on the page alongside AngularJS 1.x (ng-upgrade), then convert components one at a time, then eventually remove AngularJS 1.5 from the page.
Sometimes Reality Is In The Way
We have worked with numerous teams working on numerous medium and large AngularJS applications; and sometimes the reality is not so compatible with the idealized path described above. For older, large AngularJS 1.x projects, the upgrade path might actually look something like this:
Rewrite your AngularJS 1.x application, to follow 2015/2016 best practices, instead of the 2012 practices it is built with.
Then you can follow the recommended upgrade path to make it a Angular 2 application.
Obviously this is not an especially appealing path. We believe there will be many large AngularJS 1.x projects that simply remain in that framework for a long time to come; and this is okay, a working application does not necessarily need to be rewritten. For many applications the path to the next framework (whether that be a newer version of Angular, or one of the many competitors) is to write the replacement application far in the future, in that new framework.
For that reason and many others, perhaps the best advice is this: don’t write huge applications at all. If you have a problem space which appears to warrant a huge application, think about it carefully and divide it up into several cooperating medium-sized applications, which might appear as one from a user point of view but which are not entangled with each other technically more than necessary. With such a system design, if the day comes that it will be moved to another framework/library (Angular 2, React, Vue, Mithril, Elm, Ember, Reagent, Om, I could go on…) you have the option of converting a portion of an overall system at a time. This is both faster, cheaper, and less risky than migrating a gigantic monolith all at once.
As of March 2016 (Angular 2 beta.11) the answer is yes… or rather, yes*.
Google offers an existence proof. The Angular project leaders at Google have stated publicly (I most recently heard it on a podcast) that Angular 2 is already in production on significant projects inside Google. They mention a project with size information: around 100 developers, hundreds of components, thousands of users. It is a CRM system – they did not describe its features, but we can safely assume that it has the sorts of things you typically see in a CRM system.
(They also mention that a new version of the Adwords advertiser interface is in development in Angular 2, with a much larger team team, intended for a vast user-base, right at the heart of how Google earns money – but this project is not yet in production.)
Now for some caveats:
The Angular team was talking about internal applications – which usually implies loading over a fast network, so payload size is not very important. As of March 2016 the payload size of Angular 2 is still quite large.
Google’s large Angular 2 projects, at least the ones mentioned, are coded in Dart, not TypeScript, so they benefit from the more straightforward tooling for Dart. In fact, this makes me wonder if we should consider Dart. So far we have not, as it appears the development community is far more interested in TypeScript.
Oasis Digital’s Experiences So Far
Here at Oasis Digital we are building software for customer production deployment in the coming months, in Angular 2. We also have a large swath of Angular 2 training materials for Angular Boot Camp (already teaching Angular 2 classes). To further get our feet wet, we have even built some of our recent public-facing web properties with Angular 2 – but temporarily accepting the large payload size, assuming the size will come down before becomes a priority for us. We’ve also met teams at other companies building at scale in Angular 2.
From this experience, here are more caveats about heavy development or production use:
We work primarily on business applications where deployment payload size is not such a big deal… but extensive functionality is vital.
There has been quite a bit of churn over the last few month. Keeping up with the churn in a stack of alpha and beta tools, can use up quite a bit of time. Here at Oasis Digital we can justify it because we invest this time building up our expertise, to teach classes. It could be harder to justify an organization only building applications, looking for a stable and finished platform.
The developer experience has some critical rough edges. Unlike the competition over at React, Angular 2 offers no compile-time help with either the types or the names of any data that passes through templates. For now we recommend limiting exposure to this by moving data almost entirely outside of the template system, using it only for tableting and not for binding our components to each other more than necessary. There are other great options (Elm/Redux-like architecture, injection, Observables) for data flow. (WebStorm now offers a degree of development tool support for Angular 2 templates, though that doesn’t remove the need for Angular 2 to support it natively.)
Browser supports isn’t very complete yet – some built-in Angular 2 features (like most of the Pipes) are broken in some common browsers, though the problem can be patched with a polyfill.
The build/package story is rather rough:
Webpack is mature, but using it in development on a sizable angular 2 project is quite frustratingly slow, on Windows especially.
JSPM offers an alternate future-oriented approach, with the frustration of installing most packages twice: once via NPM so that TypeScript can see them, once via JSPM. so that the bundler can see them. This irritation may go away, if TypeScript becomes more configurable, or becomes aware of JSPM out-of-the-box.
A third approach, which seems most practical for today, is to use SystemJS but not JSPM, then use the pre-bundled Angular 2 and related packages, and perform TypeScript compilation with the –outFile option. This means minimal moving parts during development, and faster recompilation. It also makes it possible to perform TypeScript compilation in your IDE for error checking, and use that same output (rather that throw it away and compile it again via a bundler plugin) to execute in the browser.
Ready Enough
Angular 2 is ready enough to use today, to build applications at scale for production deployment – but be aware of the need to allocate ongoing technical effort to keep up with things.