
Many iterative-development thinkers have a notion of an “iteration zero” at the beginning of a project, that does not involve much software development but rather understanding the problem, choosing technology, choosing a set of features for a first major release, and so on. That work is often described as what happens at the beginning of a project, the beginning of ongoing work.
Having worked with many customers in the early stages of a project, we see a place for a small project-before-the-project. Not necessarily a first iteration to start ongoing work; but rather work before decision has even been made about when or whether to do a full project, to commit to ongoing work.
A customer comes to us, eager to show the potential of a project, but not yet in a position to commit to a long-term effort, nor eager to create a pile of non-software artifacts. Rather, they want to quickly show that something could work, how it could work, have some code in hand to serve as a working rough prototype. These needs will not be met by starting an effort that will take many months and many dollars to yield the first working result.
This is the problem we solve with a proof-of-concept engagement: One short pass through the whole development cycle. Such a project is a limited time and scope effort to understand a problem domain (just a little bit) and then write some software (just a little bit) that demonstrates the value of a customer’s idea. Such a project looks something like the description below, of course the details vary.
(A proof of concept effort is very workable for a greenfield project, not applicable inside a system that has an existing substantial code base. For those, we have another kind of initial engagement, to get an existing system up and running and survey its code base.)
Scope
- Meet with customer domain experts, typically for half the day for a couple of days. Understand enough to do initial, relevant work.
- Sketch (with a mix of code, drawing tools, and paper) what some of the most critical screens will look like.
- Verify with customer domain experts that the ideas we have captured are the most relevant to their vision.
- Implement: expand the most important aspects from mere static screens or drawings. Create working prototype code.
- Integrate working screens with other static mockup screens.
- Present the working prototype software to the customer, including source code.
- Assist the customer with installation of the working prototype in their environment, to enable easy internal demonstrations.
- Present a video demonstrating the working system, we have found this valuable especially when the prototype needs to be shown to a potentially wide audience around the customer organization.
- Discuss future steps with the customer.
The bulk of this work is understanding the problem and creating working code. A proof of concept effort is not about creating another long requirements document. It is not about working through all the details. It is about code that demonstrates a working implementation of the essence of the customer vision, demonstrating that if implemented it would solve a problem worth solving.
Technology
To get the maximum benefit from a short effort, we use technologies our team has extensive current experience with. Typically that will be (as of early 2017) Angular or React on the front-end, Node or Java on the backend. We work with numerous other technologies for production efforts, but some of them are less amenable to shipping a working result within days of project start.
Team
To delivery a working result in a a short time, the team on this kind of project consists of:
- Two core, highly experienced developers (developer / trainers)
- Assistance from other developers
- Assistance from a designer
- Assistance from a project manager
Schedule
The work happens over a 1-2 week period. Scheduling can be tough, because the developers involved will also be developers who have the deepest mastery of the technologies to be used – developers who also teach our classes, lead project teams. We work with customers to choose the right start date to do this successfully.
Location
Typically this work happens at our headquarters; with the meetings conducted with the usual remote meeting technology, or occasionally with a customer expert visiting. It is also possible to send a team to a customer site for this work – although with that variation, there is less opportunity for additional Oasis Digital team members to jump in.
Price
We charge a fixed, all-inclusive price for a fast proof-of-concept effort. Since the investment is known up front, there is no risk of exceeding an agreed budget, missing an estimate, and so on.
Where to go next
After a completed proof of concept project, our customer has working prototype software; but it is not a prototype in the sense of very poorly, hastily built code; because it is built by our instructor/developers, it is of surprisingly good quality, ready to form a starting point for a more substantial development effort.
If a development effort is warranted (sometimes the thing you learn from a working prototype, is that the idea is not worthy of major investment after all!) a customer in-house team could pick up a working prototype source code and run with it; or of course we at Oasis Digital can be involved in ongoing work.
Sounds good, how do I buy this?
This is just a blog post; there is no “buy now” button. Contact us to talk about your project, if it is suitable for proof of concept project, we can send a proposal.



 But there is at least one major exception. Angular 2.0 (which is coming soon, who knows how soon?) is built in TypeScript. You can go look right now, the source code in progress is sitting there in GitHub, and it
But there is at least one major exception. Angular 2.0 (which is coming soon, who knows how soon?) is built in TypeScript. You can go look right now, the source code in progress is sitting there in GitHub, and it 


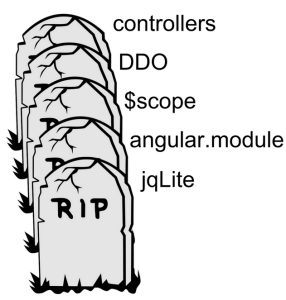 That was the conference with the infamous “tombstone” slides, and the frequently misunderstood explanation by the Angular team members that they did not have a migration strategy for Angular 1-to-2 yet. Many commenters at the time seemed to misunderstand the yet part as some assertion that there would be no migration strategy at all. Fortunately, the agitation around that initial announcement has subdued, work has continued, progress is being made.
That was the conference with the infamous “tombstone” slides, and the frequently misunderstood explanation by the Angular team members that they did not have a migration strategy for Angular 1-to-2 yet. Many commenters at the time seemed to misunderstand the yet part as some assertion that there would be no migration strategy at all. Fortunately, the agitation around that initial announcement has subdued, work has continued, progress is being made. Though there has been quite a lot of progress on Angular 2, which we have been following (much of the development is being conducted in the open) our recommendation now is that if you don’t have a reason to work with A2 well before its release, you’re probably better off ignoring it a bit longer. As I write this in August 2015, the Angular 2 alpha versions are still rather rough, particularly in the experience of getting started.
Though there has been quite a lot of progress on Angular 2, which we have been following (much of the development is being conducted in the open) our recommendation now is that if you don’t have a reason to work with A2 well before its release, you’re probably better off ignoring it a bit longer. As I write this in August 2015, the Angular 2 alpha versions are still rather rough, particularly in the experience of getting started.


 These projects sometimes involve a so-called task-based user interface. Briefly, this is an interface where the operations available to the user are presented in terms of the problem domain, rather than in terms of editing data. Other names for this idea include “task-focused user interface” and “inductive user interface”.
These projects sometimes involve a so-called task-based user interface. Briefly, this is an interface where the operations available to the user are presented in terms of the problem domain, rather than in terms of editing data. Other names for this idea include “task-focused user interface” and “inductive user interface”.
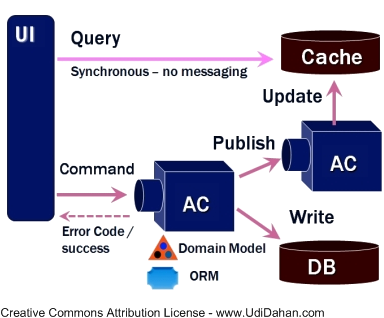
 AngularJS web application and a data service. This topic is also asked about in almost every “Angular Boot Camp” class I teach, so by posting this I have an online resource to point at.
AngularJS web application and a data service. This topic is also asked about in almost every “Angular Boot Camp” class I teach, so by posting this I have an online resource to point at.
 Do you always use the same browser, with your window the same size, with the same settings? Then your CSS is probably not robust at all. It is quite easy to accidentally style in such a way that the slightest disruption in the layout causes unexpected unpleasant results.
Do you always use the same browser, with your window the same size, with the same settings? Then your CSS is probably not robust at all. It is quite easy to accidentally style in such a way that the slightest disruption in the layout causes unexpected unpleasant results.