After the September Angular Lunch Jack discussed building an Angular app that uses the JIRA API. We work with the JIRA API on JIRA integration projects.
Transcript
We have transcribed the talk about to text, provided below.
After the September Angular Lunch Jack discussed building an Angular app that uses the JIRA API. We work with the JIRA API on JIRA integration projects.
We have transcribed the talk about to text, provided below.
I recently gave a talk about a somewhat non-traditional approach to using Agile boards in JIRA. This was recorded 2015-09-15 at our offices in St. Louis.
We have transcribed the talk about to text, provided below.
At our September 9, 2015 Angular Lunch, Mark Katerberg compared the different testing frameworks with AngularJS 1.x. He shows and explains the differences between Jasmine, Mocha and associated libraries, and how they compare for Angular application unit testing.
If you don’t have time to watch it, here is my super-high-level summary:
But don’t take my word for it. Watch the talk video, Mark has compared all of these and more.
We have transcribed the talk about to text, provided below. This is a rough, first-draft transcription, so any errors are probably from that process.
Continue reading AngularJS Testing Frameworks – Mark Katerberg – Angular Lunch
As the largest purveyor of JIRA classes outside of Atlassian, we are as keen as anyone on their plans for the future after the round of press releases and articles related to JIRA, Atlassian’s value, and a possible IPO. The news and reporting around Atlassian of late has been pretty intense, confusing, and possibly alarming.
https://gigaom.com/2015/10/06/atlassian-splits-flagship-jira-product-into-three-ahead-of-ipo/

Atlassian has a long history of being a quirky, pleasant, and technically excellent company. They just announced that they were the the #2 best company to work for in the US and #1 in Australia. Meeting their employees and listening to how they feel about the company leaves you with a very positive impression. Watching “Ship it” at the end of each Summit also demonstrates another amazing attribute of the culture, innovation.
“Ship it” is an internal 24hr hack-a-thon that happens at Atlassian every quarter. At the end of Summit they bring the best projects for the previous year and have them present to the attendees. The attendees then get to vote on their favorite (barring a voting malfunction). It is not unusual for many of the projects to already be available in the Atlassian Marketplace. I believe that was the case for three of the projects this year.
Atlassian has communicated to its employees that the team matters; that each employee is important and can add value. They have communicated the expectation that their employees will have fun and be creative. The big looming question is, can this culture remain if the company goes public?
 The founders of Atlassian as recently as last year were discussing their 50 year plan for the company. Talk like that was missing from the stage this year. I could still hear it being discussed on the show floor, but not in the main keynotes. I honestly got the sense that they knew this could be their last event together and it had a “retirement party” sort of feel. Lots of talk about accomplishments, video snippets and photos of their early years, etc. All that was missing was a toast, a roasting and a gold watch.
The founders of Atlassian as recently as last year were discussing their 50 year plan for the company. Talk like that was missing from the stage this year. I could still hear it being discussed on the show floor, but not in the main keynotes. I honestly got the sense that they knew this could be their last event together and it had a “retirement party” sort of feel. Lots of talk about accomplishments, video snippets and photos of their early years, etc. All that was missing was a toast, a roasting and a gold watch.
Now this does not mean they will cash that billion dollar check and ride into early retirement. There are many paths that can be taken from this point forward. There are examples of companies that have successfully navigated the transition and kept their culture intact. Southwest Airlines (I am on one their planes coming back from the Summit in San Francisco as I write this), is a prime example of this.
There is another big change that is rolling out now that could threaten Atlassian as well. For the first time in a decade they have changed what JIRA means in the marketplace. JIRA has been broken up into three products:
The three versions can be confusing enough but their delivery to the marketplace, while sensible, appears to me to fraught with opportunities for buyer confusion. I will do my best to explain.
If you own JIRA Software you already have JIRA Core. When you load version 7.0.0 on any platform (Cloud, Server, Data Center) you have new project templates available to you. With version 7 they added a new Project Category to bundle projects for Software and Business into different groups.
JIRA Service Desk is now a standalone project. Sort of. You can certainly buy JSD separately and install it on a server by itself. If you own JIRA Software and buy JSD you can also run it right on the same server. If you own cloud then JSD will simply show up for you, all nicely integrated. Clear as mud.
JIRA Core and JIRA Software both can be deeply customized in the traditional way you edit schemes, workflows, fields and screens. The base projects provided as a part of JIRA core are extremely simplistic and I wonder if customers will be a little frustrated at the overly basic nature of the setup.
Following are the various permutations of products users can own. A bit confusing for those of us that make applications that work with the JIRA API.
 JIRA Portfolio? The product was missing completely from the keynotes. Odd after such an emphasis the last year.
JIRA Portfolio? The product was missing completely from the keynotes. Odd after such an emphasis the last year.
It will be interesting to watch Atlassian sort through these challenges. If it were not for the looming IPO I would not have much concern. They have proven adept at improving products very rapidly and moving out of awkward situations with aplomb (HipChat anyone?). They can still do it but launching on a public or private offering would clearly run the risk of a dangerous distraction. Distraction is not what is needed when rebranding and relaunching your core product, you need intense focus.
The Summit was fantastic and Atlassian is an amazing company. Lets hope we say the same of them this time next year.
(The usual warning: This is code from a couple weeks after Angular 2Alpha 45 – if you’re watching this months later, things may have changed!)
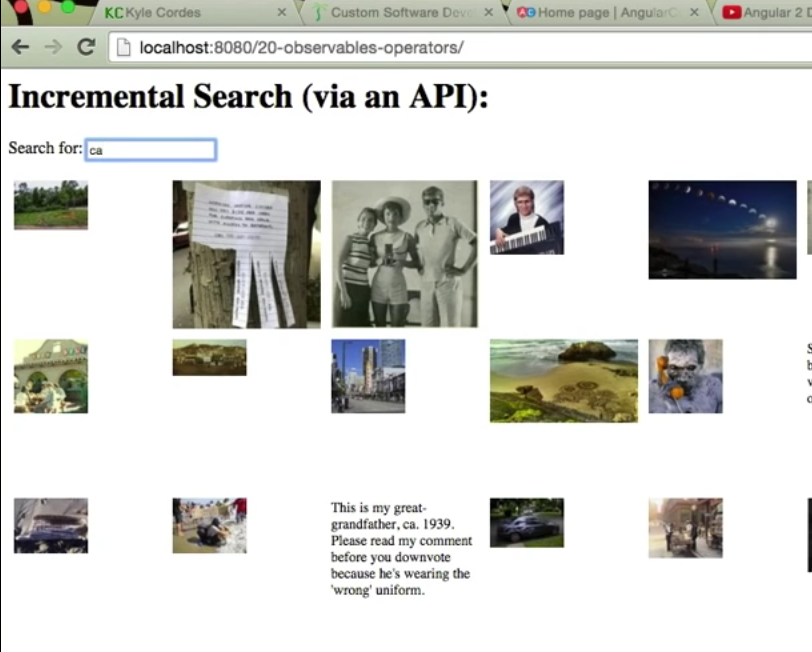
A few weeks ago at the Angular Connect conference in London, the core Angular team presented on the new Observable data flow and related concepts available and under development in Angular 2. Sharp-eyed viewers have tried to copy the code they presented and run it, but found that it does not actually work yet. But not all hope is lost, and it is not necessary to wait. As I write this at the beginning of November 2015, it is possible to run and see the exact kind of demo they presented, in action.
In this video, I present the running code, and explain it (as best I understand, keeping in mind that many of the relevant pieces are not yet documented…) line by line.
Today we finished teaching our first Angular 2 class. This was our “Early Start with Angular 2“, a special, preview two-day version of what will soon be a three-day class – or perhaps even longer. This was an “alpha” class, using alpha materials, covering an alpha product, but in spite of that it went well. More importantly, it gathered positive reviews from the students, several of whom commented that the class answered important questions they had and other questions they didn’t even know they had, about Angular 2.
Paul Spears and I (Kyle Cordes) taught this one – In the coming months our other instructors will be getting up to speed on the new technology also.
Angular 2 is a considerable step upward in terms of learning curve compared to Angular 1. This is because it is built on more powerful abstractions and libraries, most notably RxJS / ReactiveX / RxNext. As always, if you’re looking for help learning or adopting Angular (1.x or 2) please contact us. We have two more Early Start classes, then after that we will teach the full three-day version.
Toward the end of our Angular class we typically present some example code that uses various Angular concepts in an integrated way. Here is one of those examples, explained on video. In this example we show how to use directives to abstract away many of the details of complex data entry forms.
Of course the whole point of a live, human led class is that we take questions and guide the material to meet the need of the students, and that doesn’t work on video. But it still should be enjoyable for anyone learning AngularJS.
This example is from our AngularJS version 1 class, in the future I will present snippets of Angular 2 also.
In this post I’m going to share a few tricks for using Hibernate tooling in CQRS read models for rapid development.
Hibernate is extremely popular. It’s also deceptively easy on the outside and fairly complex on the inside. It makes it very easy get started without in-depth understanding, misuse, and discover problems when it’s already too late. For all these reasons these days it’s rather infamous.
However, it still is a piece of solid and mature technology. Battle-tested, robust, well-documented and having solutions to many common problems in the box. It can make you *very* productive. Even more so if you include tooling and libraries around it. Finally, it is safe as long as you know what you’re doing.
Keeping SQL schema in sync with Java class definitions is rather expensive a bit of a struggle. In the best case it’s very tedious and time-consuming activity. There are numerous opportunities for mistakes.
Hibernate comes with a schema generator (hbm2ddl), but in its “native” form is of limited use in production. It can only validate the schema, attempt an update or export it, when the SessionFactory is created. Fortunately, the same utility is available for custom programmatic use.
We went one step further and integrated it with CQRS projections. Here’s how it works:
Thanks to this, much of the time you don’t have to we almost never type SQL with table definitions by hand. It makes development a lot faster. It’s similar to working with hbm2ddl.auto = create-drop. However, using this in a view model means it does not actually lose data (which is safe in the event store). Also, it’s smart enough to only recreate the schema if it’s actually changed – unlike the create-drop strategy.
Preserving data and avoiding needless restarts does not only improve the development cycle. It also may make it usable in production. At least under certain conditions, see below.
There is one caveat: Not all changes in the schema make the Hibernate validation fail. One example is changing field length – as long as it’s varchar or text, validation passes regardless of limit. Another undetected change is nullability.
These issues can be solved by restarting the projection by hand (see below). Another possibility is having a dummy entity that doesn’t store data, but is modified to trigger the automatic restart. It could have a single field called schemaVersion, with @Column(name = "v_4") annotation updated (by developer) every time the schema changes.
Here’s how it can be implemented:
public class HibernateSchemaExporter { private final EntityManager entityManager; public HibernateSchemaExporter(EntityManager entityManager) { this.entityManager = entityManager; } public void validateAndExportIfNeeded(List<Class> entityClasses) { Configuration config = getConfiguration(entityClasses); if (!isSchemaValid(config)) { export(config); } } private Configuration getConfiguration(List<Class> entityClasses) { SessionFactoryImplementor sessionFactory = (SessionFactoryImplementor) getSessionFactory(); Configuration cfg = new Configuration(); cfg.setProperty("hibernate.dialect", sessionFactory.getDialect().toString()); // Do this when using a custom naming strategy, e.g. with Spring Boot: Object namingStrategy = sessionFactory.getProperties().get("hibernate.ejb.naming_strategy"); if (namingStrategy instanceof NamingStrategy) { cfg.setNamingStrategy((NamingStrategy) namingStrategy); } else if (namingStrategy instanceof String) { try { log.debug("Instantiating naming strategy: " + namingStrategy); cfg.setNamingStrategy((NamingStrategy) Class.forName((String) namingStrategy).newInstance()); } catch (ReflectiveOperationException ex) { log.warn("Problem setting naming strategy", ex); } } else { log.warn("Using default naming strategy"); } entityClasses.forEach(cfg::addAnnotatedClass); return cfg; } private boolean isSchemaValid(Configuration cfg) { try { new SchemaValidator(getServiceRegistry(), cfg).validate(); return true; } catch (HibernateException e) { // Yay, exception-driven flow! return false; } } private void export(Configuration cfg) { new SchemaExport(getServiceRegistry(), cfg).create(false, true); clearCaches(cfg); } private ServiceRegistry getServiceRegistry() { return getSessionFactory().getSessionFactoryOptions().getServiceRegistry(); } private void clearCaches(Configuration cfg) { SessionFactory sf = entityManager.unwrap(Session.class).getSessionFactory(); Cache cache = sf.getCache(); stream(cfg.getClassMappings()).forEach(pc -> { if (pc instanceof RootClass) { cache.evictEntityRegion(((RootClass) pc).getCacheRegionName()); } }); stream(cfg.getCollectionMappings()).forEach(coll -> { cache.evictCollectionRegion(((Collection) coll).getCacheRegionName()); }); } private SessionFactory getSessionFactory() { return entityManager.unwrap(Session.class).getSessionFactory(); } }
The API looks pretty dated and cumbersome. There does not seem to be a way to extract Configuration from the existing SessionFactory. It’s only something that’s used to create the factory and thrown away. We have to recreate it from scratch. The above is all we needed to make it work well with Spring Boot and L2 cache.
We’ve also implemented a way to perform such a reinitialization manually, exposed as a button in the admin console. It comes in handy when something about the projection changes but does not involve modifying the schema. For example, if a value is calculated/formatted differently, but it’s still a text field, this mechanism can be used to manually have the history reprocessed. Another use case is fixing a bug.

We’ve been using this mechanism with great success during development. It let us freely modify the schema by only changing the Java classes and never worrying about table definitions. Thanks to combination with CQRS, we could even maintain long-running demo or pilot customer instances. Data has always been safe in the event store. We could develop the read model schema incrementally and have the changes automatically deployed to a running instance, without data loss or manually writing SQL migration scripts.
Obviously this approach has its limits. Reprocessing the entire event store at random point in time is only feasible on very small instances or if the events can be processed fast enough.
Otherwise the migration might be solved using an SQL migration script, but it has its limits. It’s often risky and difficult. It may be slow. Most importantly, if the changes are bigger and involve data that was not previously included in the read model (but is available in the events), using an SQL script simply is not an option.
A much better solution is to point the projection (with new code) to a new database. Let it reprocess the event log. When it catches up, test the view model, redirect traffic and discard the old instance. The presented solution works perfectly with this approach as well.
Often I describe JIRA as a large set of Legos in a bucket. JIRA is one of those tools that is so flexible it is hard to get your head around how to use it.
The Lego analogy works on many levels. Using the predefined project types, JIRA Agile, JIRA Service Desk, etc is like opening Lego kits. Yes, they still include regular legos, but the fun stuff only works when it is built in a certain way, and will only make what someone else imagined. While working with the standard block shapes you can put together almost anything you can imagine. With this in mind, there are three main components of JIRA that make up the core building blocks of a system: issues, workflows, and filters.
Every feature in JIRA revolves around one of the three. I want to focus on filters and their broad impact in JIRA. It is incorrect to think of all the issues in JIRA broken up into projects because this is simply not true, even a project is simply one filter of the greater issue store. All the issues created in your JIRA instance are in the same bucket. When JIRA moves to display items to the user it first looks to see what subset of issues this user has permission to see (regardless of project), and then shows the list based on the filter being used at the time.
A good way to think of this concept is the diagram included here. There is the larger issue bucket of the whole instance, and individual users can see the issues that span the projects, issue security, and permissions given to them. They are then able to apply filters within that cross-section they have rights to.
Filters are used for all Reporting, Agile boards, Dashboard Gadgets, Wallboards, API calls, and of course filtered issue lists. If you are looking at more than one issue on your screen, filters are at work.
Once you grasp this idea you can really start to use filters in a powerful way. I often see the light bulb come on in either day 1 or day 2 of our JIRA Boot Camp class. Users will often say, “So that is why <insert situation here> happens!” and then they will be empowered to fix some long-standing problem that has caused frustration with JIRA.
An important aspect of filters that is often overlooked is sharing. The lack of understanding runs across a wide spectrum. On one end people struggle with the idea that users cannot see a particular Agile board or a gadget on a Dashboard without having the necessary filter shared with them. Often in these environments the company is only organizing everything at the project level. These are also often the companies that only use the built-in issue types and avoid customized workflows. They will find it hard to have desired data and functions available where users need it.
The other extreme is the system where everyone automatically shares every filter with all users. In this situation people can easily get frustrated by having hundreds and sometimes thousands of filters to deal with. Over time the list just gets larger and larger as employees come and go within the company. Imagine if an average employee has 25 filters and the company turns over 100 employees per year. In two years you could have 5000 abandoned filters in the system.
It does not help that the interface adds confusion to an already complex idea. in the words of Inigo Montoya:
“You keep using that word, I do not think it means what you think it means.”
On the main filter page is this big, obvious button that says “Share”. This is not actually how you share a filter! You must click into the less obvious “Details” hyperlink and add permissions to the filter. I do hope this gets fixed soon by the removal or re-purposing of the share button.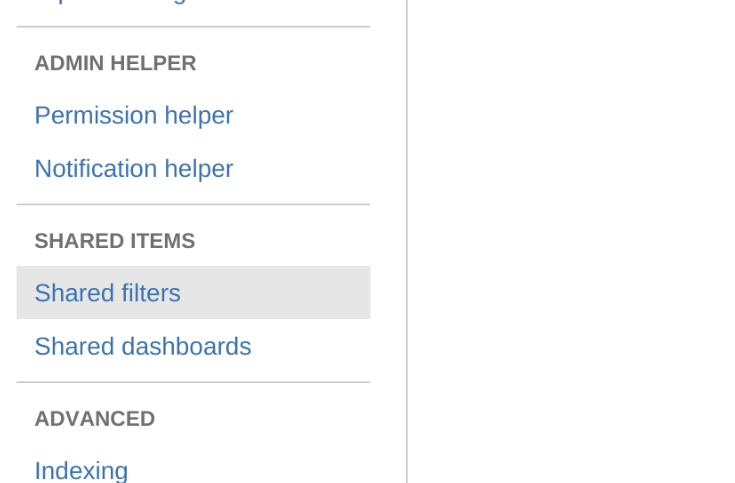
Neither of these extremes is actually necessary. The proper balance is to have an intentionality to sharing of filters and an administrative discipline to curate the issue list in the System Admin area of JIRA. See the image shown. In this area an admin can delete abandoned filters and change ownership of important ones. Keeping this list manageable is simply good JIRA hygiene.
Filters are a core building block of JIRA. Understanding them and guiding your users to apply them properly can dramatically improve the user experience.
Technology platforms mature and improve over time. The Atlassian ecosystem is no exception. One area where Atlassian has matured dramatically is in supporting customizations. In the past customizations were a real “wild west” edit the database and file system approach. Today we have flexibility in configuration and a strong API. Often people have a hard time letting go of history, especially with technology we feel has failed us. There are many that assume that any customizations are unwise in JIRA. I wanted to cover JIRA customization and contrast the past with the reality of today. Later in the article I will lay out a few best practices as well so you can get what you want from JIRA without risking too much.
In the not-too-distant past, a typical JIRA installation might have played out something like this:
A group in a company obtains a copy of JIRA Server, installs it, and immediately jumps into configuring all the admin screens to get projects running. They start by using one of the built-in workflows with all the standard transitions. As usage expands, needs are found and are either accommodated by the administrator or met by a nifty add-on that did what was wanted out of the box.
Once in awhile something very specific will be desired to increase efficiency or user adoption, so the admin will go in and modify the database, add some scripts, or edit some of the configuration files directly. A few months later they realize they cannot upgrade JIRA because they would lose all their customizations that they depend on–or perhaps worse, they upgrade and most of their functionality is broken.
 Some companies invest the hours to fight through the upgrade pain and customize a much newer version, but many companies simply stay at a very old version until the application is abandoned. I recently spoke with a company that was still stuck using 4.x, while 7.x is the current version! This cycle is far more prevalent than people realize. Many smaller and mid-sized companies find themselves in this position, I have multiple students in every class facing this very specific dilemma.
Some companies invest the hours to fight through the upgrade pain and customize a much newer version, but many companies simply stay at a very old version until the application is abandoned. I recently spoke with a company that was still stuck using 4.x, while 7.x is the current version! This cycle is far more prevalent than people realize. Many smaller and mid-sized companies find themselves in this position, I have multiple students in every class facing this very specific dilemma.
Fortunately JIRA customization is far different today than it was a couple of years ago. Atlassian has done a great job moving to a clean API that allows for significant external input while increasing the flexibility of the system. There is a new danger I will talk about in a moment but customization can live across version upgrades today, unlike in the past.
I typically describe JIRA as a big box of legos. Used properly there are few scenarios that cannot be accommodated with the base system. When approached in an educated way it is incredibly flexible. Here are some guidelines around customizations I share when consulting on JIRA implementations.
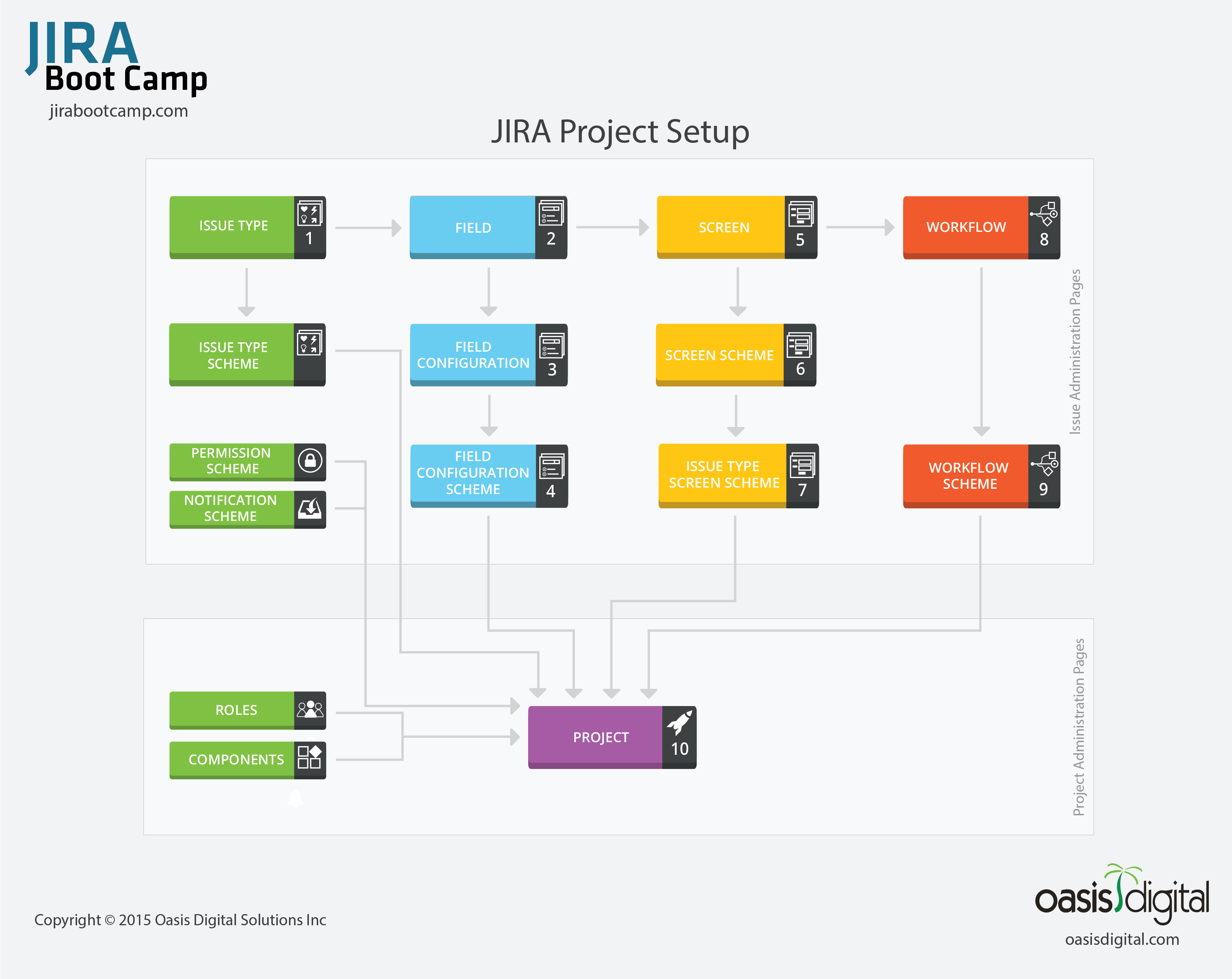
Understand completely how projects come together. Utilize “Custom Issue Types” to break up your workflows, allow for clearly defined field configurations, and ultimately better reporting. Here is the diagram we use in our classes to teach students how to correctly put together a project.
If you follow these best practices (which may need to be modified over time), you are not guaranteed to completely avoid problems. But In our experience you are far less likely to be caught in a situation where an upgrade breaks your customizations. Unlike a couple of years ago we encourage customization as long as you stay on the safe path.
JIRA is easy to get, inexpensive, and generally accepted as a great tool. It is very easy to get off the safe path and into the weeds with such a configurable and powerful tool. Good training and best practices are a sensible choice.
One of the biggest benefits of CQRS is the ability to implement multiple read models. Business rules and the domain model are safe, clean and isolated over in the write model. They are not getting in the way of view models, which can selectively pick the pieces they are interested in, freely reshape them, and do everything in a way that needs different kind of elegance and clarity as the domain model. The read models are all about query performance and convenience.
Put simply, CQRS is a practical implementation of what Pat Helland described in his paper on immutability: The truth is the log. The database is a cache of a subset of the log. Let’s have a look at some consequences of this approach.
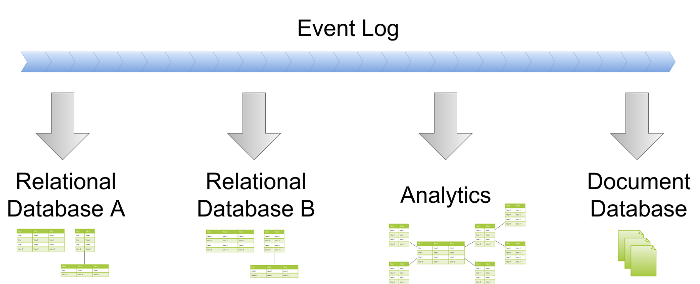
Perhaps the most obvious way to implement a read model is in a traditional SQL database. The technology has been around for decades, is really mature and battle-tested, and everyone is familiar with it.
However, in the CQRS world we can do things that would be problematic in a typical application database schema. Since we optimize for read convenience and performance, the data is very often denormalized. It can happen in a number of ways:
You may be wondering why one would be using a denormalized schema in the first place. The answer is: to do more computation ahead of time, while processing events and while no human is waiting for the answer. It means less computation at the moment a human is waiting for the answer.
The reason for this is that human time is expensive and getting more so, while computing power and storage is already extremely cheap and getting even cheaper. It is worth doing potentially a lot of computation in advance, to save a human a little bit of time.
The degree of denormalization depends mainly on performance and query complexity. Fully normalized schema has its benefits, but also many drawbacks. Numerous joins, calculations and filters quickly become tricky to write and maintain. They can also become performance nightmare, for example with joins between massive tables. Even if you’re not joining many thousands of rows, nontrivial calculations can keep the users waiting.
Denormalization can be used to prepare the answers for queries. If a query needs data that would normally live in several large tables, they can be combined once (in asynchronous projection), and then looked up in constant or logarithmic time when the users need it. It may even be possible to go to the extreme and precalculate responses to all common queries, eliminating the need for higher-level caching. In this case the view model is the cache.
It’s necessary to look for balance here, though. Overly aggressive denormalization can lead to poor maintainability related to code duplication, as well as increase the sheer volume of data (in terms of bytes).
If the data doesn’t have to be relational, or if it can be denormalized, it may be a good idea to put it in a different kind of database. There is a wide range of NoSQL options to choose from, with the most obvious candidates being document and key-value stores.
We don’t have to stop there though – if the data could benefit from a graph database, there are no obstacles. Another great example of a view model are search indexes like Lucene.
Such stores often have their downsides. They may be trading off consistency for availability and performance. They may be very specialized or limited to particular models (graphs, documents, key-values etc.). It makes them challenging or even inapplicable as the primary persistence mechanism in a typical non-CQRS read/write model. However, they may be perfectly acceptable in a CQRS view model, and the advantages make the whole thing even more powerful.
Another idea we have been considering is in-memory models. Writing to and reading from disk is slow, and if the data fits in RAM, why not just keep it in memory, in ordinary data structures in your language of choice?
There are some challenges:
These challenges could be solved by using persistent, transactional storage:
It’s getting close to persistent projections, but there are important differences. In this case persistence is only used for isolation and a way to resume from the savepoint after restart. Disk IO can happen asynchronously or less frequently, without slowing down the writer and queries.
Most queries are only interested in relatively recent data. Some may need a year or two, others may only be interested in the last week. With the source data safe on the domain side, the read models are free to keep as little as they need. It can have huge positive impact on their performance and storage requirements.
It’s also possible to have a number of models with identical schema but different data retention. Use the smaller data set as much as possible for best responsiveness. But still have the ability to fall back to a bigger data set for the occasional query about the faraway past, where longer response time is acceptable.
This approach can be combined with different granularity: Keep all the details for the last few weeks or months, and aggregate or narrow down for the longer time period.
NoSQL stores, analytics, search indexes, caches etc. are all very popular and useful tools, and very often they are used in a way resembling CQRS without acknowledging it. Whether they’re populated with triggers, messaging, polling or ETL, the end result is a new, specialized, read-only view on the data.
However, the more mature and the bigger the project, the harder it is to introduce such things. It may become prohibitively expensive, with missed opportunities eventually leading to many problems down the road.
It’s much, much easier if you have CQRS from the beginning. The domain model is kept safe and clean elsewhere, as is the ultimate source of data (like event store). The data is easily available for consumption (especially with event sourcing). All it takes to spin off a view model is plug in another consumer to the domain events.
The view models are very good candidates for innovation, too. It’s really easy to try various kinds of databases and programming languages, as well as different ways of solving problems with the same tools.
As mentioned in some previous posts, TypeScript is a very useful tool (language) for writing more correct code in larger JavaScript applications, and with Angular 2 (and at least one of its competitors) built in TypeScript, TS is likely to gain a lot more popularity.
To help anyone still getting started, I have translated the sample “phonecat” application used in the AngularJS 1.x tutorial, to TypeScript. See the link below.
https://github.com/OasisDigital/phonecat-typescript