Co-authored by Paul Spears and Andrew Wiens
1.0 Introduction
Smooth, highly-responsive interfaces increase users’ confidence in an application and create an overall positive experience. Whereas small applications with simple interactions are built without a focus on runtime performance, standard approaches sometimes do not scale well as the data size or feature complexity increases. A common scenario that may be familiar to the reader is a table that works well with small quantities of data but begins stuttering and lagging when the amount of data is increased. This guide will show how to increase performance in these kinds of applications.
Additionally, high framerates enable developers to build entirely new types of applications with Angular. Introducing animations and interactive graphics create new and exciting ways to engage with users. Here at Oasis Digital, we used the techniques in this guide to build an interactive visualization for issue tracking [1], multiple customer projects and a demo application that showcases the kind of performance that is possible within an Angular application [2].
Although we typically write Angular applications with relatively little concern for what Angular does behind the scenes, in performance-sensitive applications we achieve the desired responsiveness by knowing more about how Angular works. In this regard, an app’s implementation can have a large effect on performance: while Angular’s change detection system can complete hundreds of thousands of cycles in a few milliseconds for simple changes, application logic takes the overwhelming majority of time to execute. In this guide, we will describe how to meet the expectations of performance-sensitive applications, explain the relevant parts of Angular change detection, and highlight potential pitfalls along the way.
2.0 Toward 60 Frames Per Second
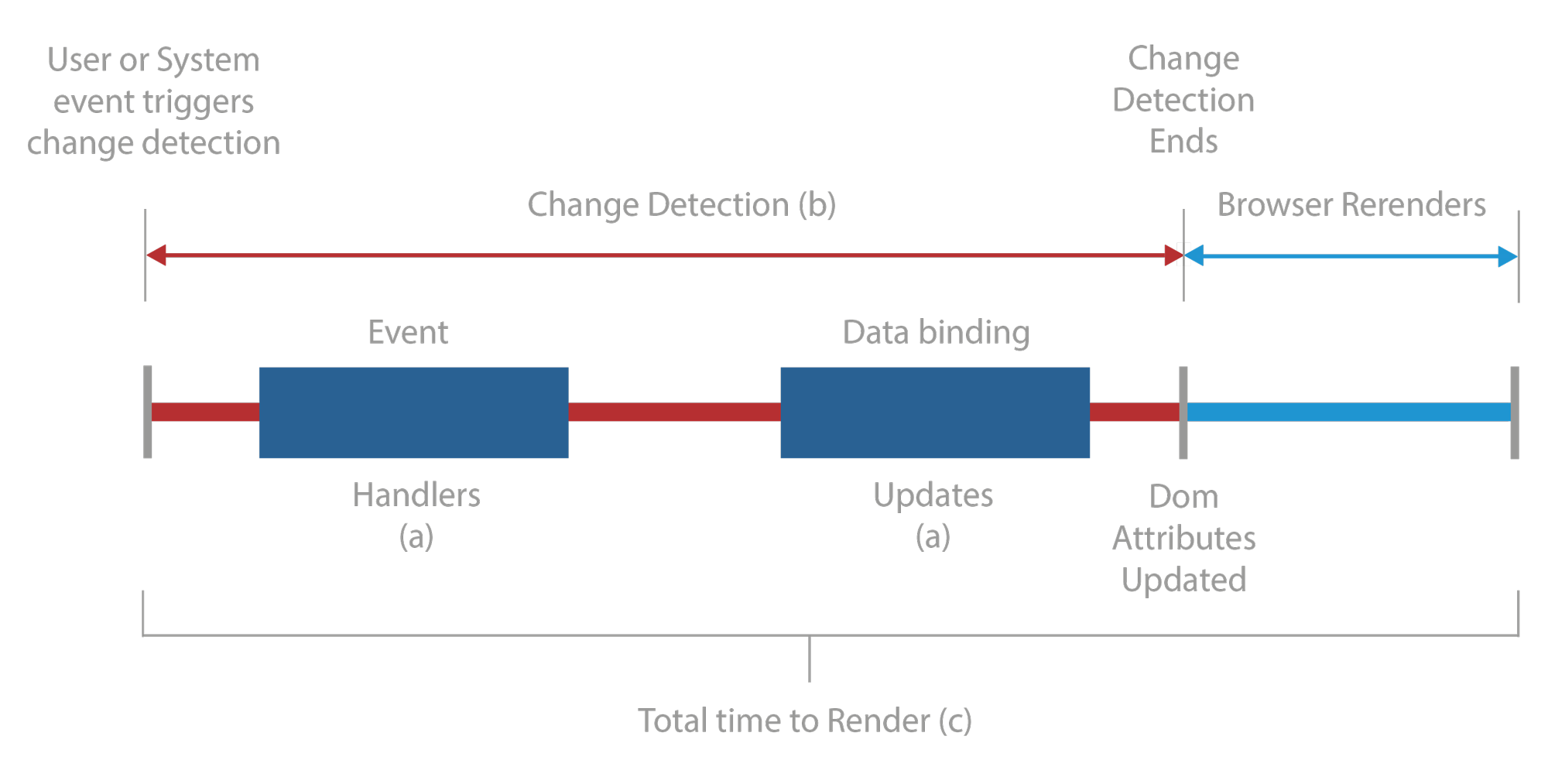
Fig. 1. Top level overview of execution control during change detection. Angular (red) calls application code (A; dark blue) during change detection (B) and updates the DOM. The browser (light blue) then updates the view, completing the change detection cycle (C). This cycle must complete in less than 17ms to achieve 60 FPS.
In the industry, 60 frames per second is the gold standard for application responsiveness, and any application that achieves it must render updates in less than a mere 17 milliseconds. Performance most often suffers in Angular applications when responding poorly to user input or other regularly-occurring events. The total time to re-render a view in response to any changes can be split into three parts: First, as shown in Figure 1A, application-specific callbacks are executed. Second, Angular’s change detection system runs as shown in Figure 1B. This system is responsible for delegating control to the application callbacks and using the results to notify the browser of any necessary DOM updates. The third piece in this process, the browser, paints the required changes. The application then waits for additional input before repeating this cycle (Figure 1C).
Since we generally only have control of our own code and how it interacts with Angular, improving runtime performance tends to involve optimizing three main aspects of our app:
- Executing application event handlers quickly
- Reducing the number of callback executions needed to complete a change detection cycle
- Reducing the execution duration of Angular’s change detection cycle
As the last two of these three aspects may imply, Angular’s change detection system has a substantial effect on runtime performance. Thus, it is important to gain a basic understanding of how the change detection system operates.
3.0 Angular Change Detection System
Once an Angular application is loaded, Angular listens for user events and other asynchronous events. Angular understands the context for these events and calls the appropriate handlers. After these handlers return, control is given back to Angular to perform change detection. Although Angular knows the data bindings between components, changes in other values may affect the template as well. For example, a template element may depend on a property of a shared object. Therefore, by default, the change detection system responds to updates by re-evaluating the template expressions of all components. If the change detection system determines that the value of a template expression has changed, it interacts with the browser to modify the corresponding portion of the DOM.

Fig. 2. Stepwise explanation of an Angular change detection cycle.
For example, a tree of components is shown in Figure 2. In this diagram, child components reside within their parents, and events can occur within any of the components. When a DOM event occurs, Angular will call the associated application event handler. Depending on how the application is structured, this may result in a component event firing rather than a DOM event. If a component event does fire, the associated event handler in the parent component is called, and this process is repeated. Once all events have been handled, Angular begins checking components and their templates for updates. This process starts from the root and works its way down to the leaves in a breadth-first manner.
Although this view of the change detection system is sufficient for our purposes, there are additional resources that explain the inner workings of this system. For a deeper explanation of Angular’s change detection system, see the blog posts from Victor Savkin and Nrwl.io [3-4].
4.0 Executing event handlers quickly
Event handlers can exist in numerous locations within an Angular application. The most obvious examples are DOM and component event bindings. An application responds to events such as mouse clicks or key presses by providing Angular a callback to execute as shown in Figure 3.
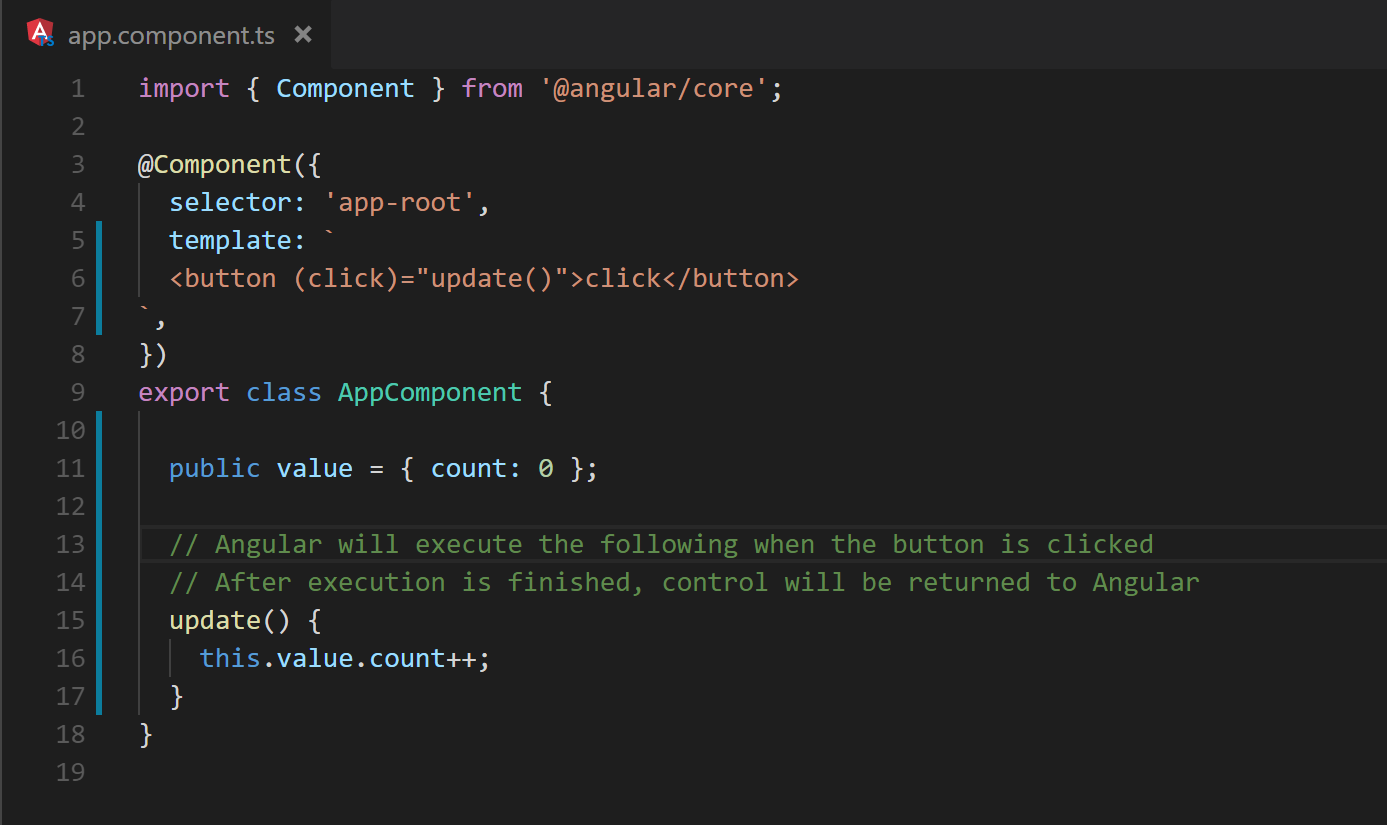
Fig. 3. A button executes a callback when clicked, effectively blocking change detection until the callback completes.
When such a callback is executed, Angular must wait for the callback to finish before change detection can continue. Once all events are processed, the change detection process evaluates template data bindings to determine which DOM properties to update. This process includes checking and updating component inputs. Angular provides developers control over how a component should respond to changes to its input bindings in the form of callbacks – OnChanges and input setters – which affect the execution time in a similar manner as event handlers.
The callbacks of event bindings, OnChanges, and input setters are the primary mechanisms for passing data between services and components in an Angular application, and it can be difficult to keep these slim. However, it is not always obvious how much code is executed during these callbacks.
4.1 Event Bindings
It is common practice to use event bindings for communicating user updates to shared locations such as services or components at a higher level of the hierarchy. Figure 4 shows a trivial example.
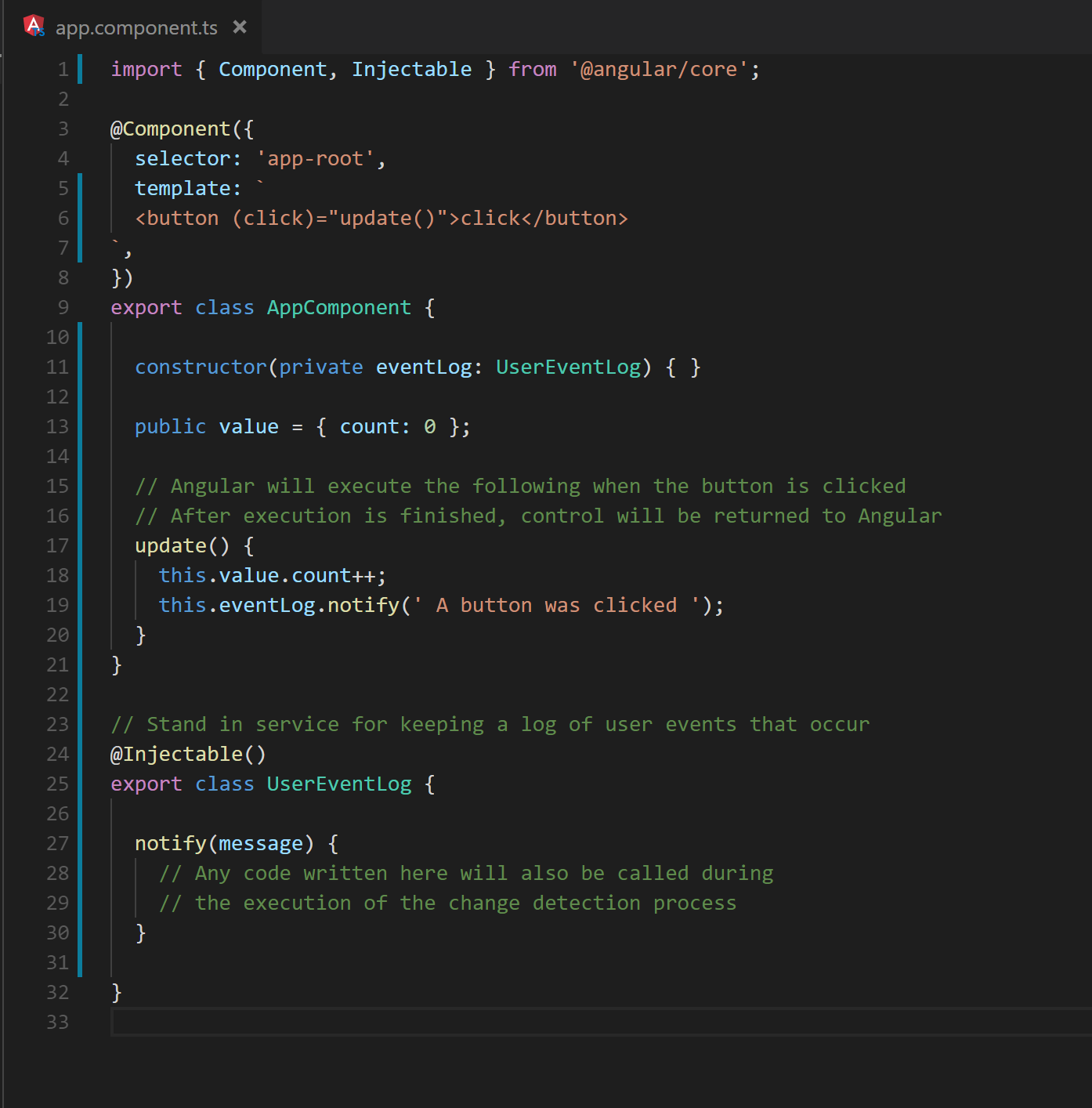
Fig. 4 A DOM event handler results in the execution of a service method.
As control moves between location,s additional processing is often required. For example, a search term combines with an array to produce a filtered list. The following code in Figures 5 and 6 demonstrates how a button click hands control to a long running service from the component. The service, in turn produces the filtered list.
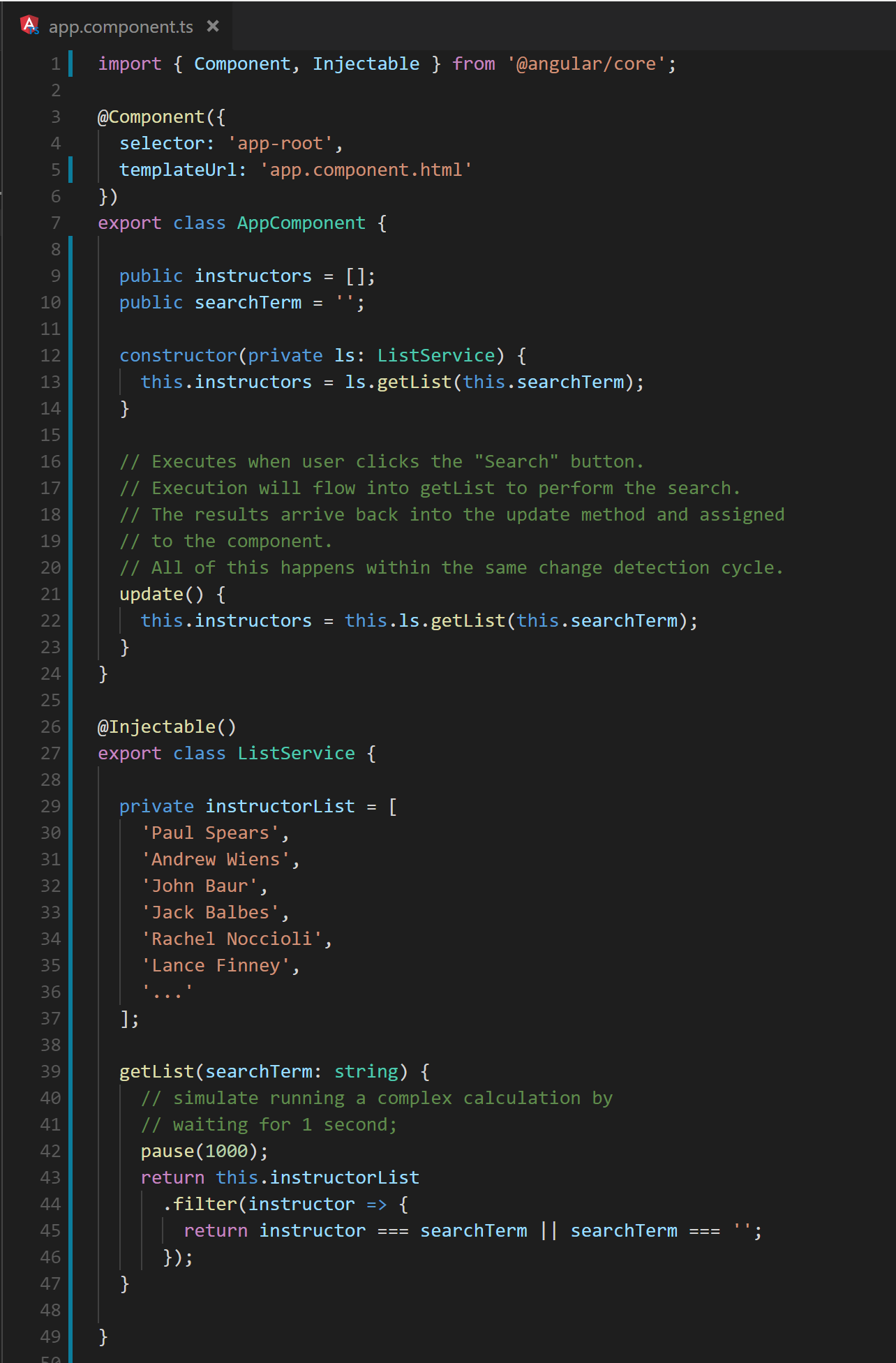
Fig. 5 A component and service cooperate to produce a filtered list of instructors.
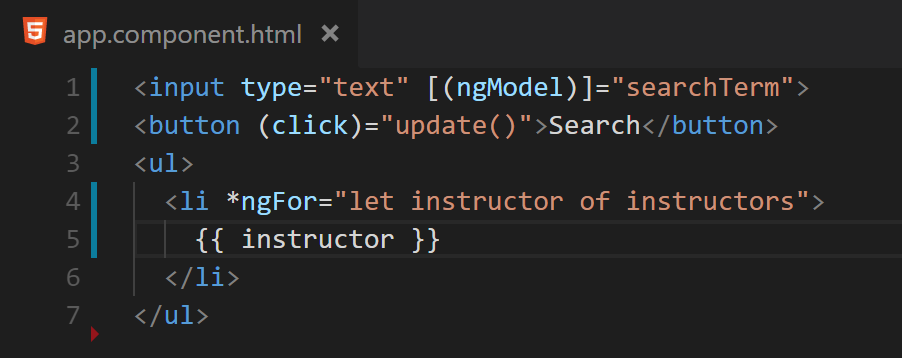
Fig. 6 The results of the calculation of Figure 5 are displayed on the screen with an ngFor.
Thus, a single event can percolate through multiple layers. By default, this computation will occur as part of the change detection cycle started by the original event binding. Figure 7 shows a stack trace of the click handler, change detection and the multiple layers of application code. Notice the “Long process” near the bottom of the image. This was inserted on line 42 of Figure 5 to emulate a calculation that could take longer than normal to run. The trace visually demonstrates that the change detection process cannot complete until all callbacks and their subsequent method calls have finished executing

Fig. 7 A stack trace demonstrating control flow during a click event.
Though not always obvious it is important to remember that function calls usually executes as part of change detection regardless of where they reside. A key to performance is being cognizant of this fact and writing code that respects it.
The pattern of calculating a new application state from user and system events is often used with great success in many enterprise scale applications. In particular the use of a library such as ngrx/store or redux strongly encourages it. In these situations, it is important to ensure that any reducers execute as efficiently as possible. Also, as we will see in the later section on RxJS Observables, it is also possible that event handlers may update an Observable. If the Observable pipeline executes synchronously, as in Figure 8, the cost of this computation is added to the total cost of the change detection cycle.
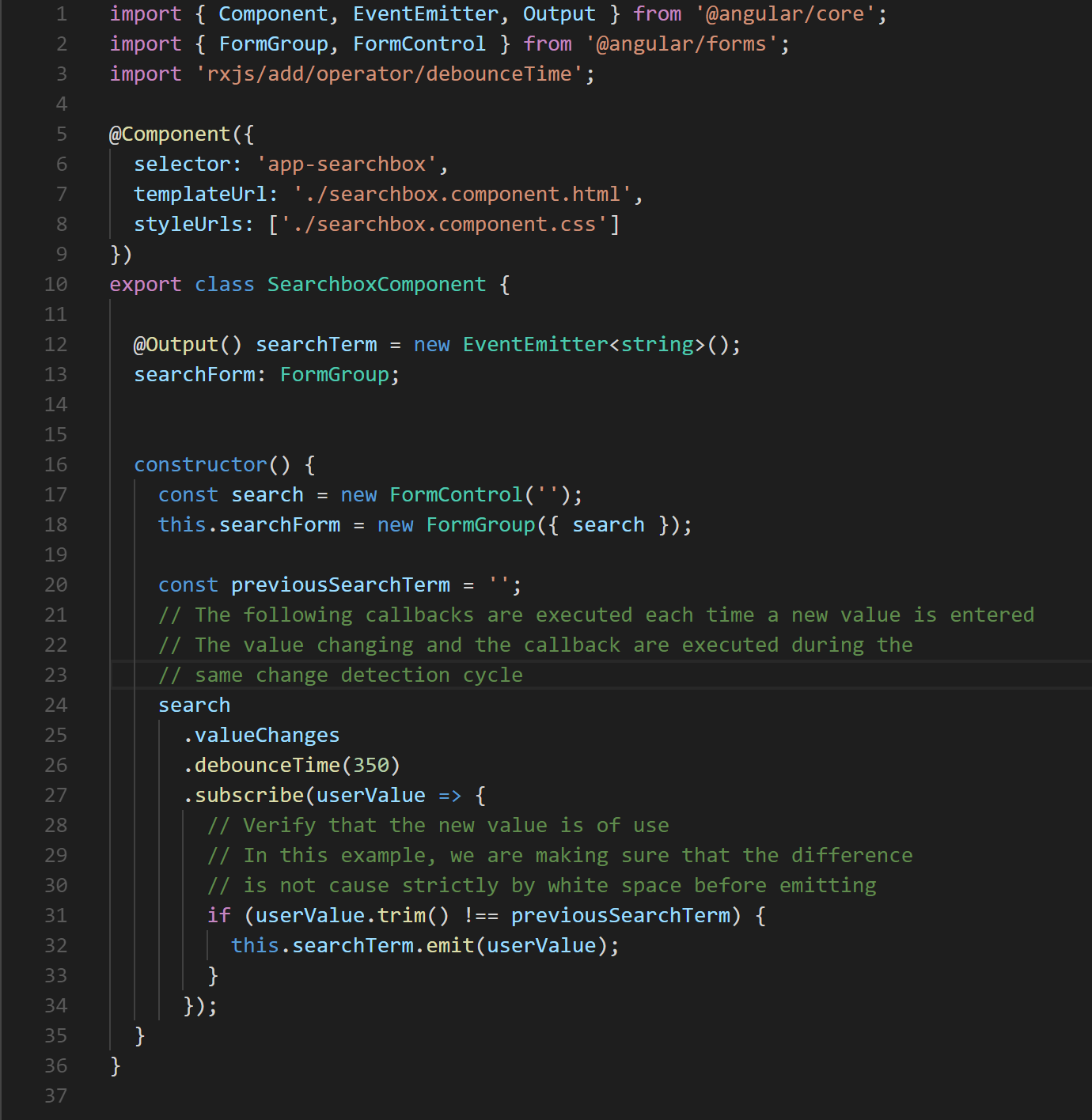
Fig. 8 The anonymous function defined on line 27 is executed as part of any change detection cycle in which the search value is updated.
4.2 Component Input Setters and OnChanges
Event handlers are not the only application code that executes during a change detection cycle. After event propagation completes, Angular continues the change detection cycle by updating the component hierarchy and template data bindings. As mentioned above, this process starts at the root component and works down towards the templates of the leaf components. Along the way, Angular will execute any setter methods associated with component inputs. Similarly, the ngOnChanges methods, similar to those in Figure 9 will be executed in components that implement OnChanges.
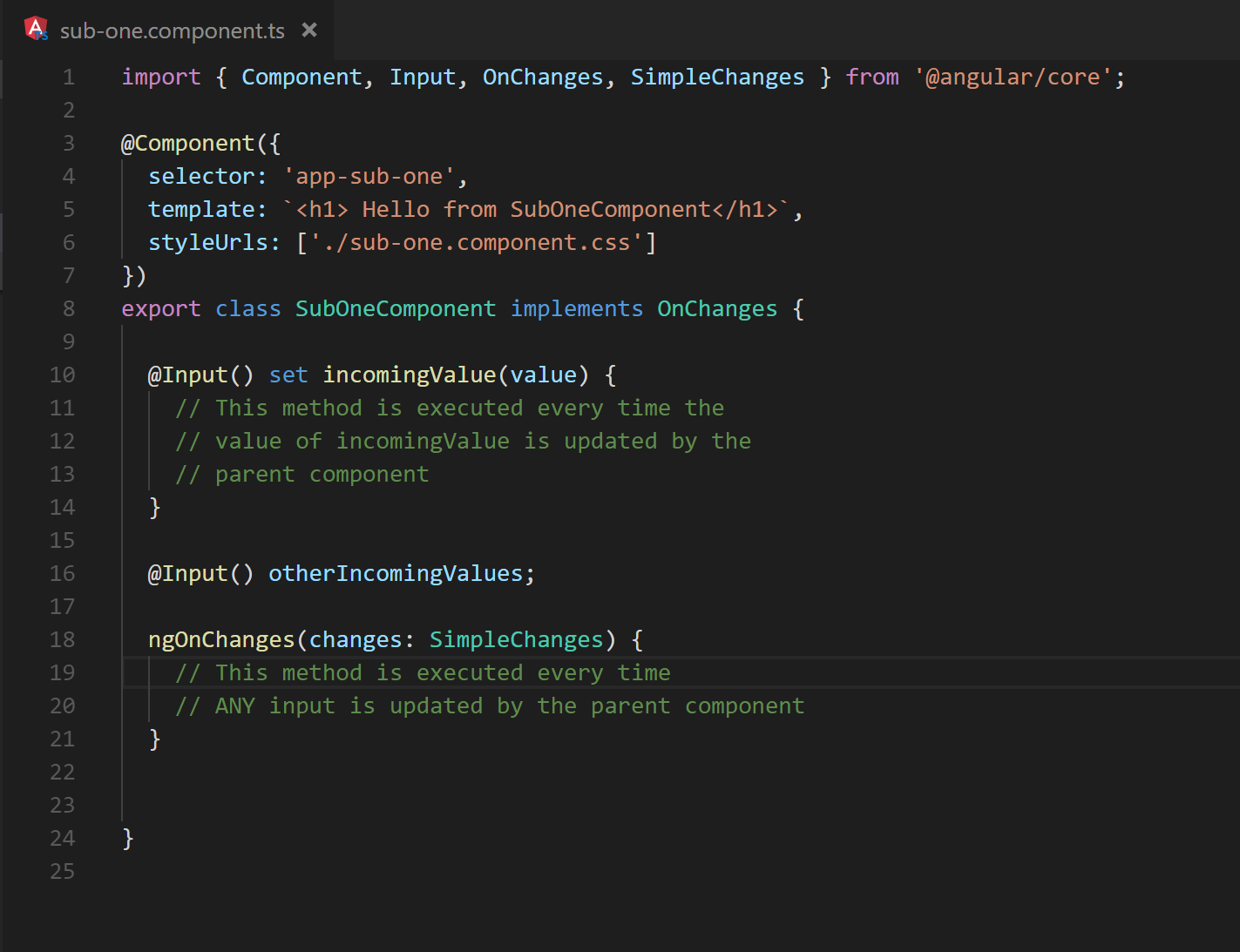
Fig. 9 Line 18 demonstrates the syntax for a basic ngOnChanges method.
Generally, problematic situations are created in the callbacks of the input setters and ngOnChanges relatively infrequently. It is often easier to spot problems when they do occur as issues are usually isolated to a single component. However, there are still a couple hazardous scenarios to point out. It is usually recommended to compute any state or UI changes needed as part of the event propagation phase of the change detection cycle. However, some situations may still occur that encourage the use of OnChanges to compute additional state needed locally within a component. Consider the filtered list example: For the sake of argument, assume that the current filter criteria and the unfiltered list are only available as inputs, and the filtered results must be computed immediately prior to display as shown in Figure 10.
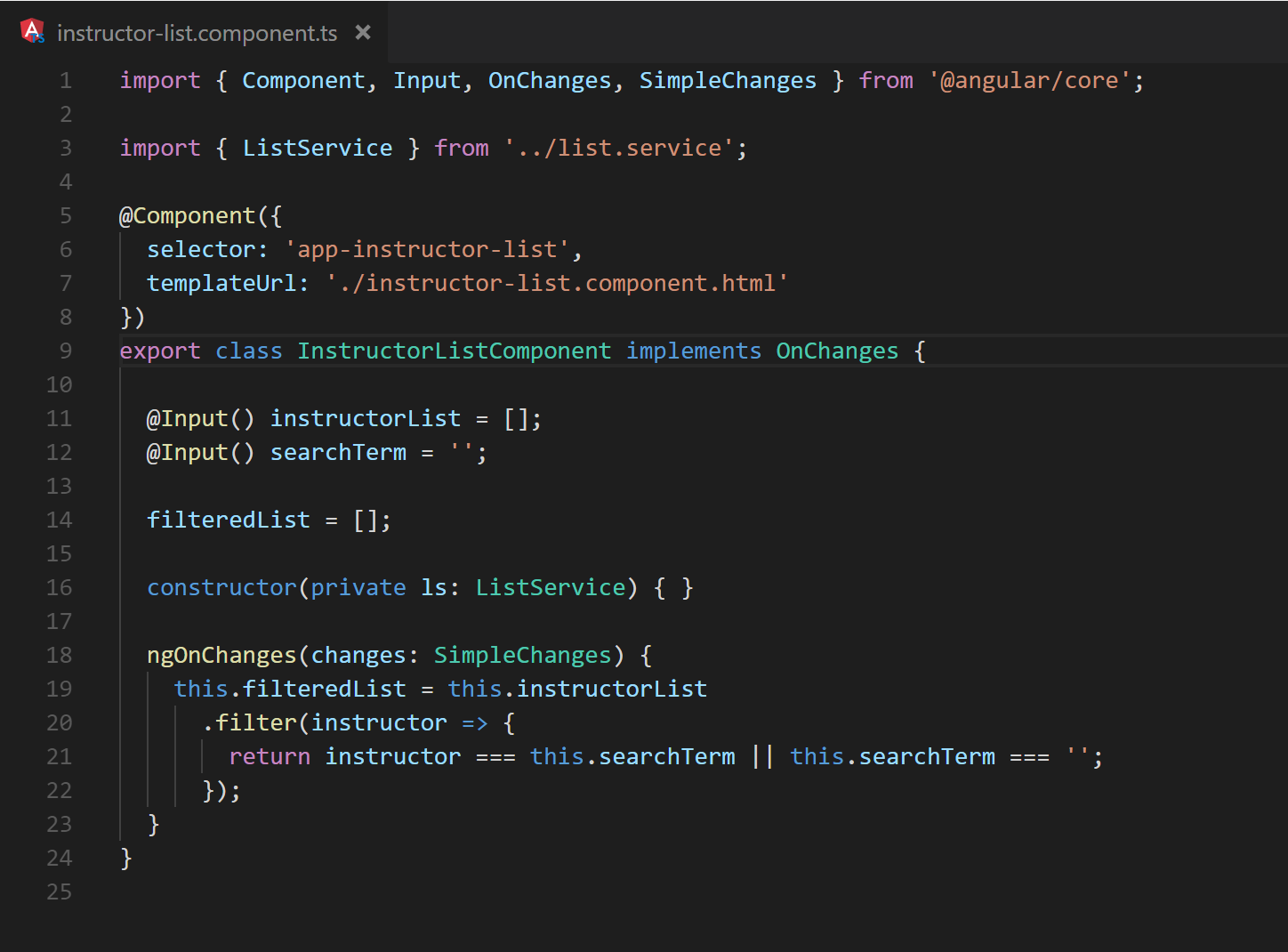
Fig. 10 Demonstration of recalculating a filtered list as Input values update
This could be achieved by utilizing OnChanges. However, doing so would cause every input change to trigger a recalculation of the filtered list. If another input were added to the component (see Figure 11), there would be a wasted calculation every time the new input value is changed.
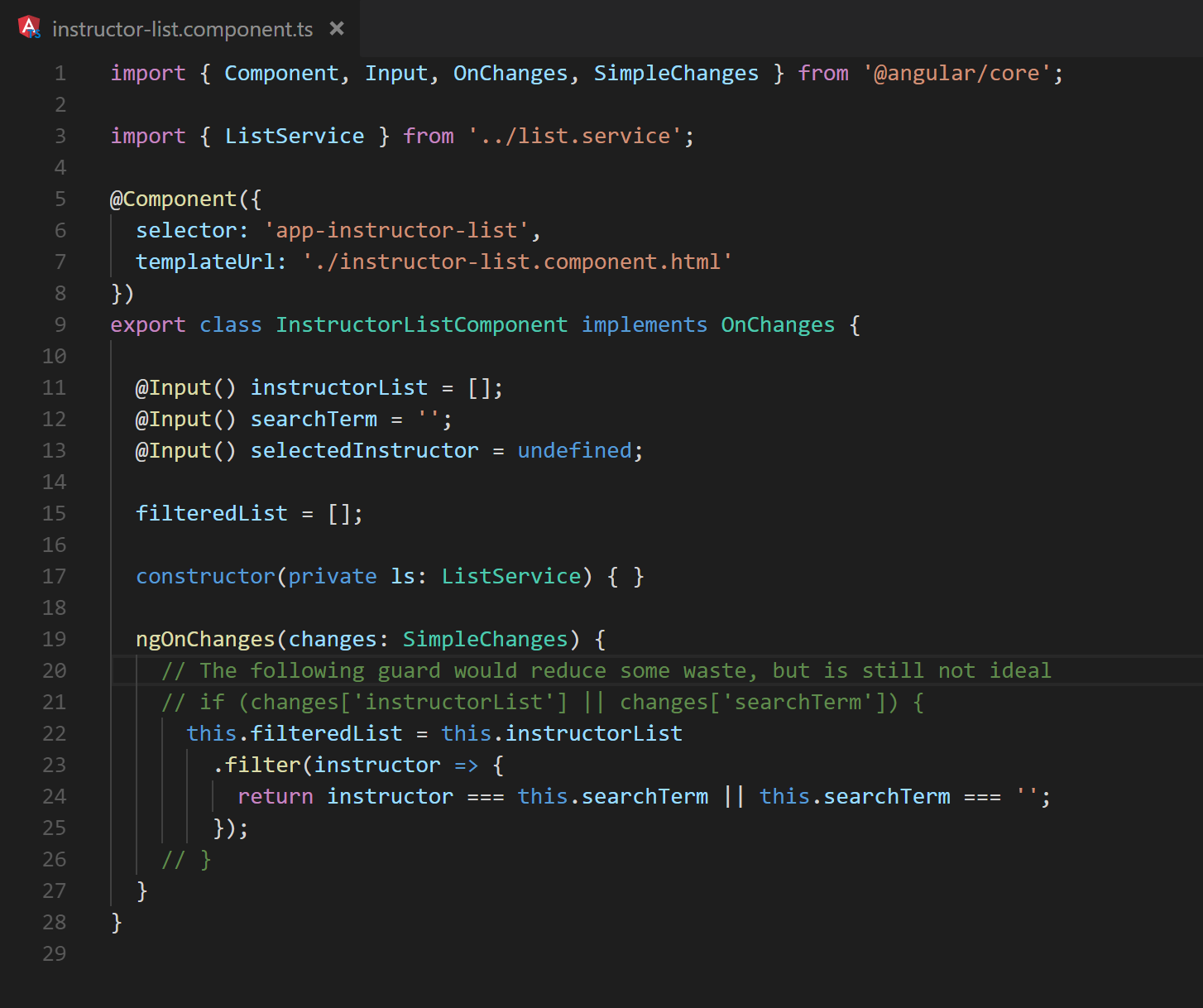
Fig. 11 The ngOnChanges method defined on lines 19 – 27 demonstrate a extraneous calculations that occur when the selectedInstructor is updated
Input setters serve a similar purpose as OnChanges, however they only fire in response to updates to a corresponding input. Generally speaking, the use of input setters will lead to more performant change handlers as there is no need for identifying which input changed, nor will it be called more often than is necessary. Although the granularity of input setters make for a better default choice, it is still possible to populate the callbacks with expensive operations, and they should be treated with the same level of care as OnChanges.
5.0 Reducing the quantity of call back executions needed
Executing application event handlers during change detection has the potential to hand execution control to multiple services and components. Being mindful of how the change detection cycle hands control to the various callbacks can help reduce its overall run time. For example, the updated values of any reactive form controls are passed to their subscribers, and the associated callbacks are then executed. This can be particularly costly if the application is undergoing a rapid succession of user input. If a debounce (.debounceTime) operator is applied to the value changes, then any processing is deferred until the input has settled. Figure 12 demonstrates the use of debounce by reducing the number of subscription callbacks that are executed. In this example the only values that are operated on are changes that occur after 350 milliseconds of stability to the search term.
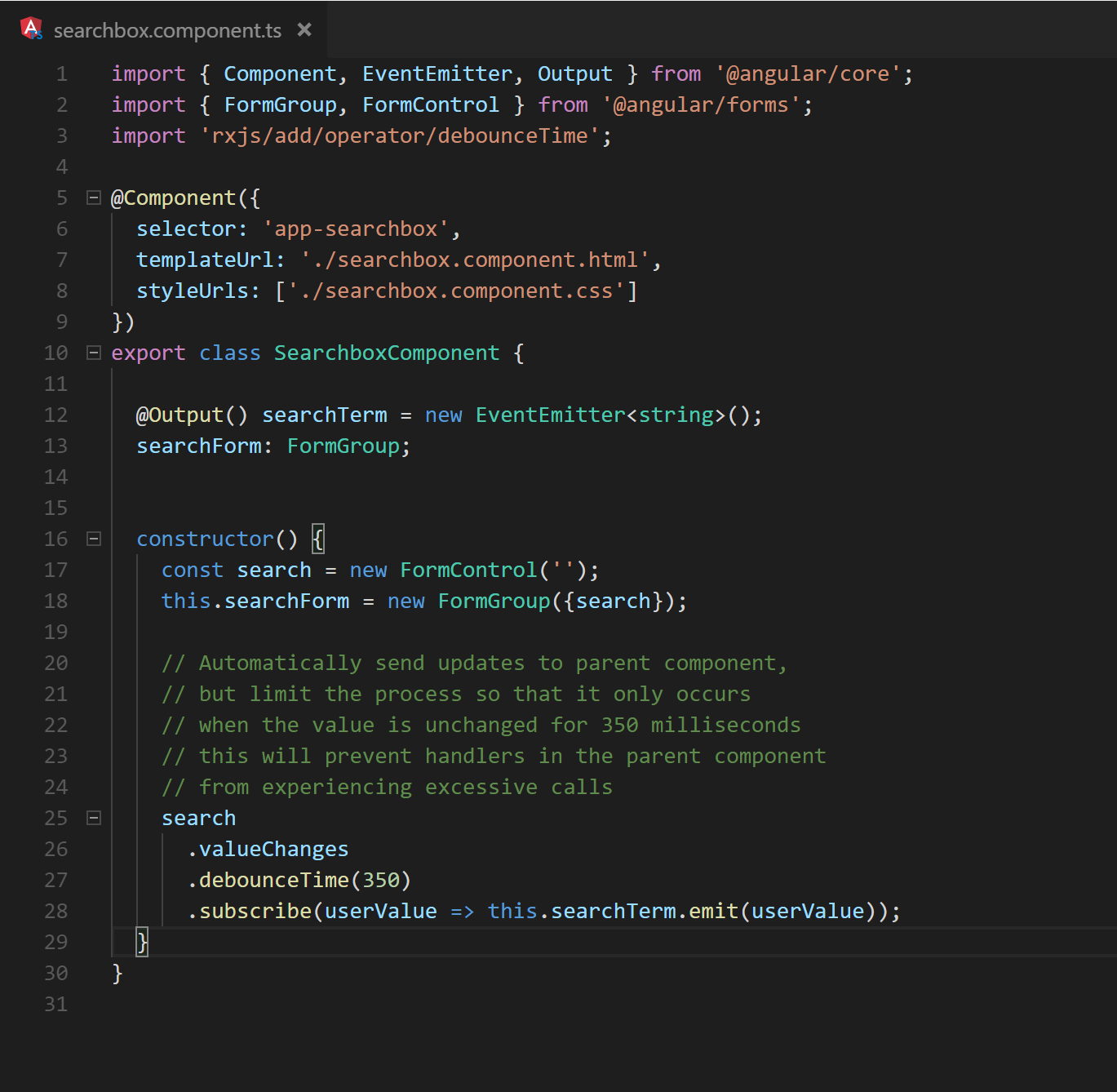
Fig. 12 A list filtering example that debounces the user’s input
Similarly, when choosing to emit values to event emitters, any duplicate events whose processing does not provide value should not be emitted. Figure 13 demonstrates this by emitting search terms instead of acting on them immediately. However, it only emits values that have a semantic difference to the previous value.
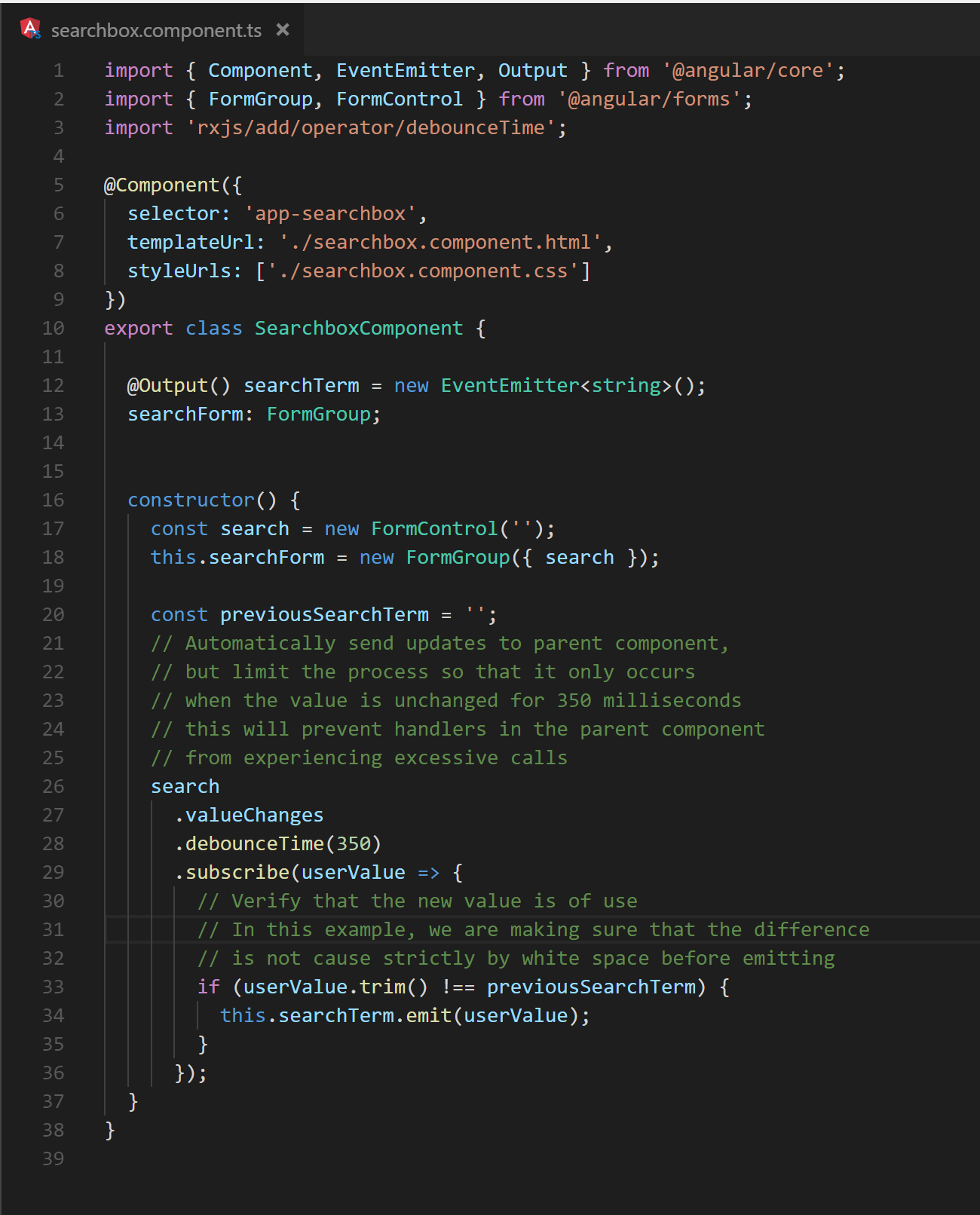
Fig. 13 A demonstration of selectively emitting values based on context
Also, when working with data-bound objects, Angular calculates equality by reference. This means that OnChanges will fire each time a bound object’s reference changes even if its content has not. Being intentional about changing such backing data can reduce the number of unneeded OnChange and input setter executions.
5.1 Controlling change detection
The effects of carefully controlling which callbacks are executed are magnified when taking direct control of change detection. The description provided earlier concerning change detection was based on Angular’s default behavior. However, Angular has an API that provides additional methods for controlling how and when change detection runs. The first of these APIs, ChangeDetectionStrategy.OnPush, will change the behavior of change detection for a given component. When applied, the change detection process will skip the component unless one of its inputs change or an Observable connected to an async pipe in its template receives an update. Consequently, any child components, located within the component’s template, will also be skipped. The change detection process can thus be reduced to only checking exactly what is needed to render changes by structuring the application to take advantage of this API. Figure 14 illustrates what this looks like by showing the step-wise checks that take place in one such scenario.
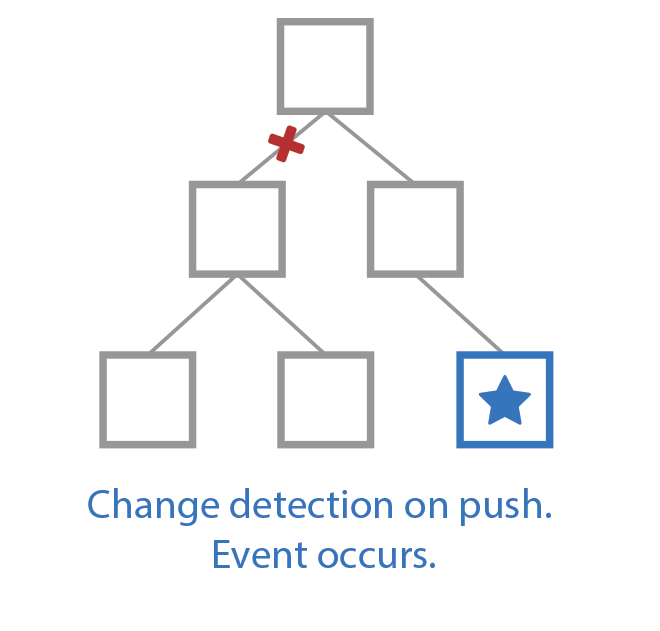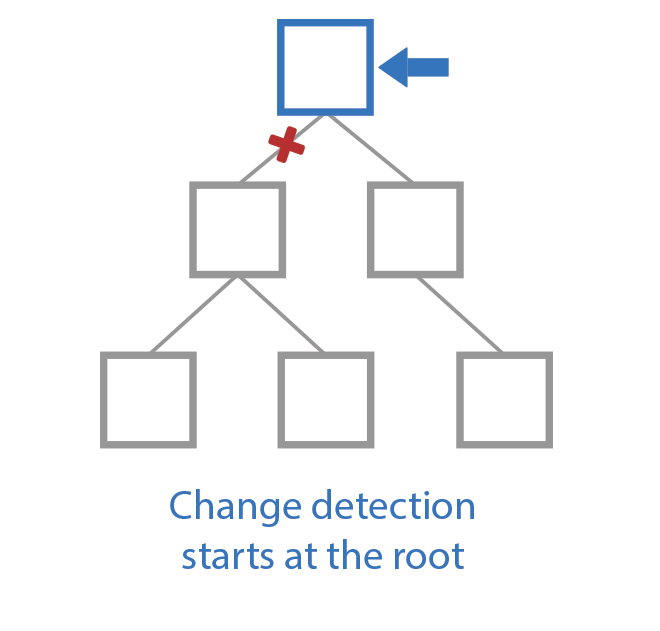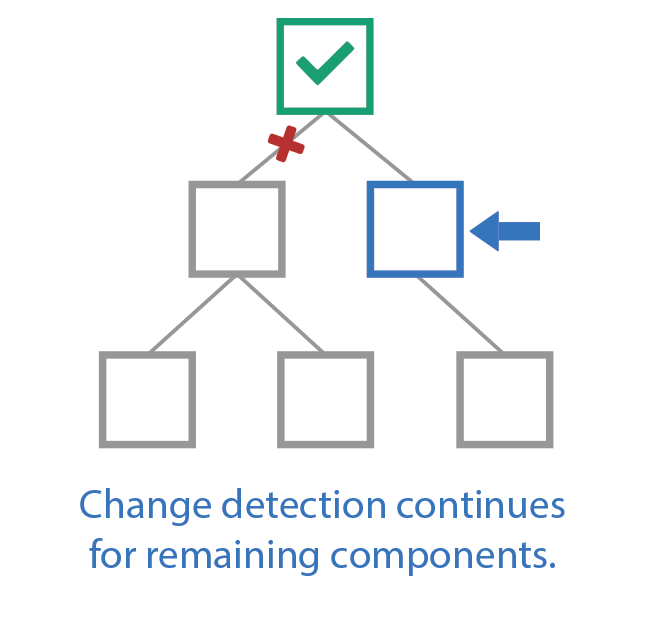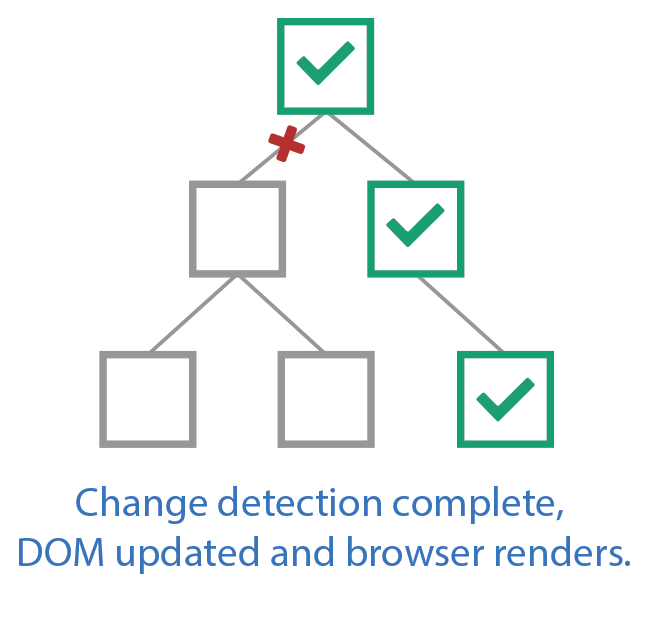 Fig. 14 Demonstration of change detection with OnPush in play
Fig. 14 Demonstration of change detection with OnPush in play
Utilizing this new strategy the filtered list code above can easily be rearranged to meet such a requirement as demonstrated in Figures 15 – 17.
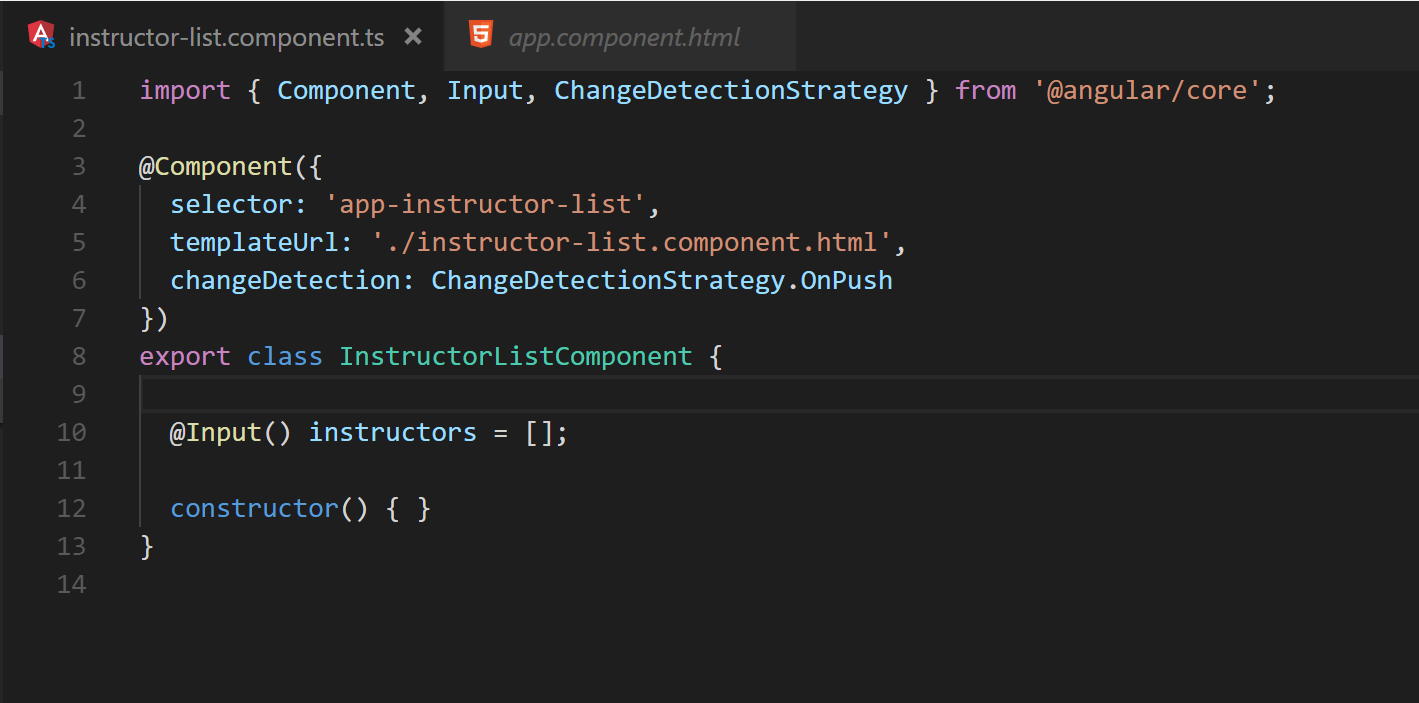
Fig. 15 The instructor-list component written to utilize OnPush. Notice that Inputs are the only source of change
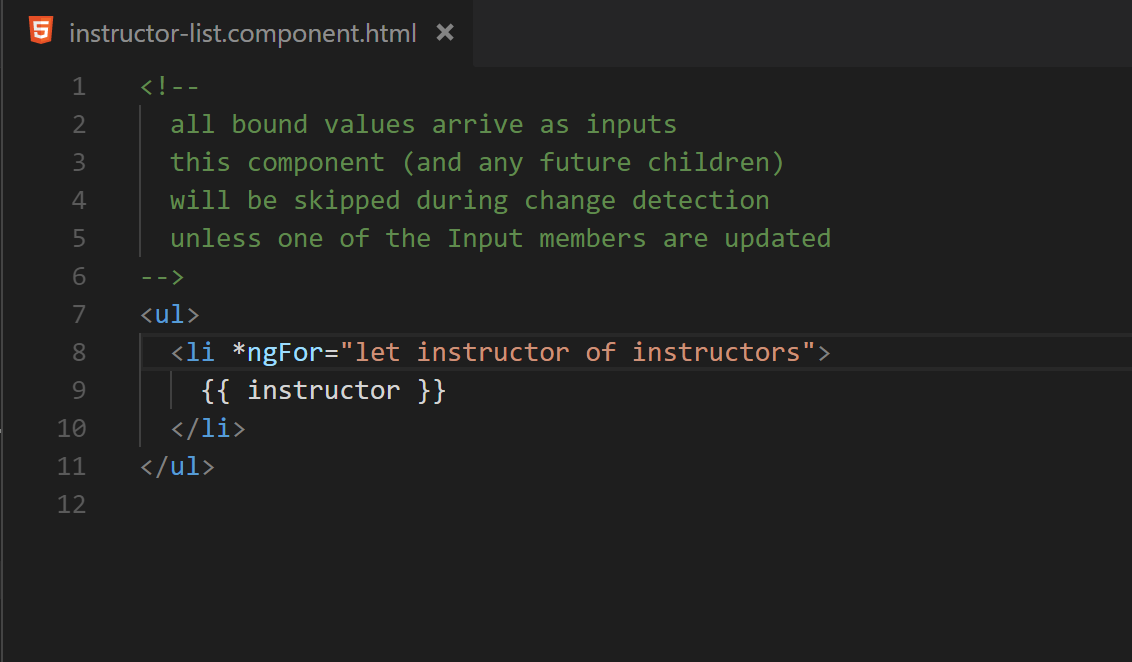
Fig. 16 The template for the instructor-list component is also free of data mutation.
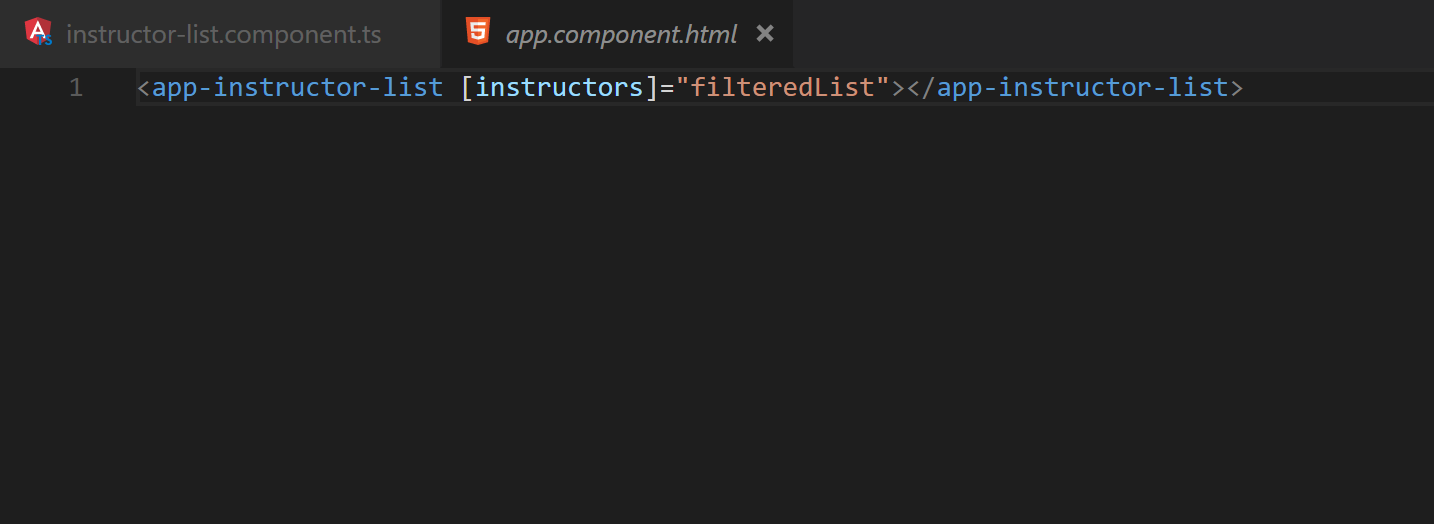
Fig. 17 The app-component html indicates that the filtered list is computed before providing it to app-instructor-list.
Alternatively, it is also possible to request that change detection be stopped entirely for a component. Figure 18 demonstrates some of the options available when controlling change detection manually. How to use this properly and effectively is highly dependent on the situation. It is rare that performance issues need this level of control to be resolved and its use should be reserved for exceptional cases.
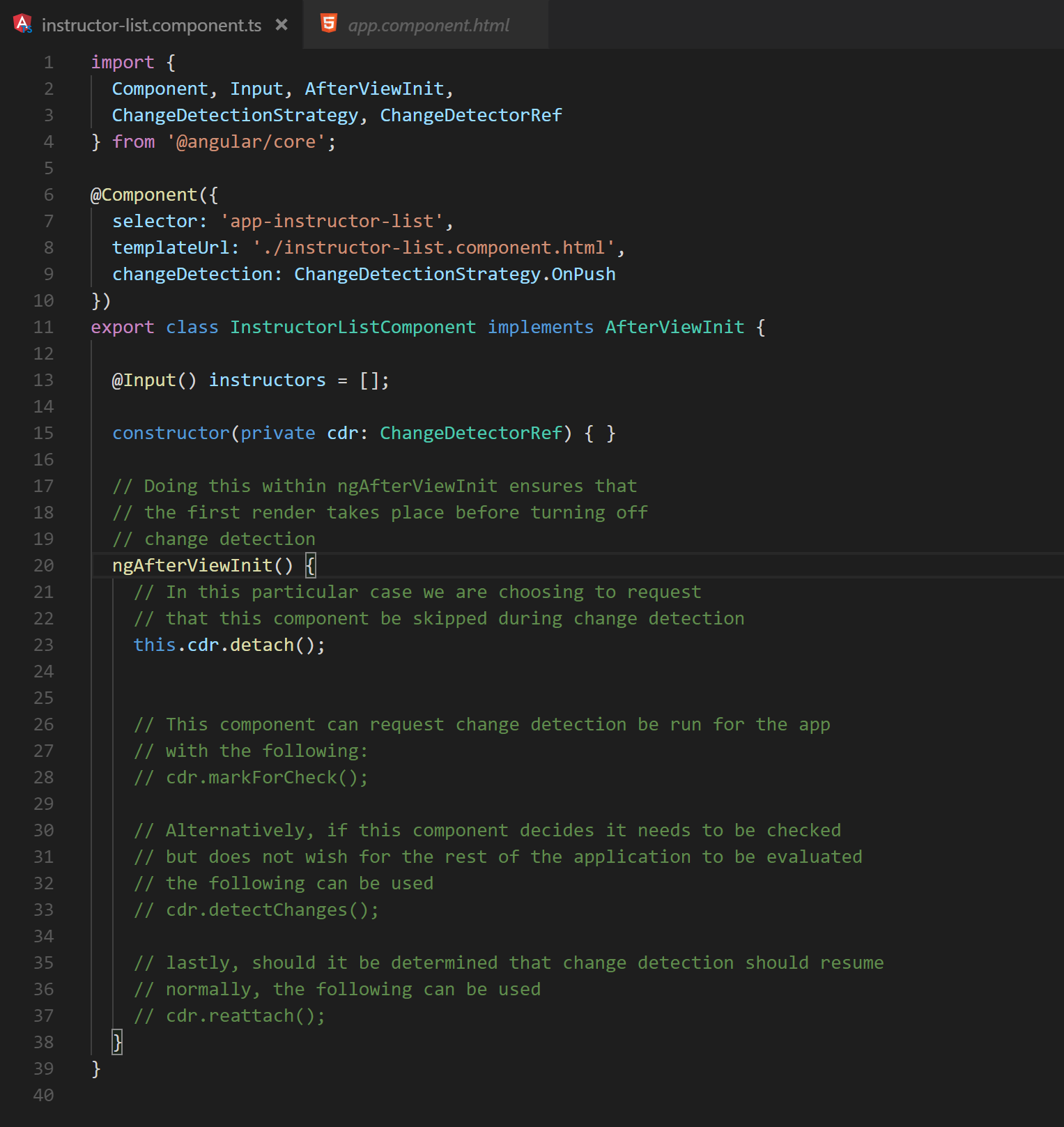
Fig. 18 A brief highlight of the API available for manual change detection
Another way to control change detection is to execute long-running code outside of change detection entirely. If a particular block of code can be executed asynchronously, Angular provides an API to mark a callback to run outside of change detection. Using this API will allow the current change detection process to complete and the browser to rerender. The callback will then execute; when it finishes, a new change detection cycle will begin to display the results.
Example Coming Soon!
For particularly expensive calculations, a web worker can be used in conjunction with manual change detection. The following repository contains an example that runs d3 force calculation – a particularly expensive operation – inside a web worker [2]. The results are returned after completion, and Angular is informed that change detection is needed using a component change detector reference.
https://github.com/dpsthree/angular-performance-playground/blob/master/src/app/d3-helper.service.ts
6.0 Reducing the duration of change detection
During change detection, Angular checks which data bindings need to be updated to apply the most recent changes. Features built into Angular can be leveraged to speed up this process; similarly, there are pitfalls that can make this process slower.
6.1 Template Methods
Angular has a very convenient feature that allows binding data directly to the result of a method call. By using Angular’s template binding syntax to assign an attribute to a method, the results will be recalculated with every change detection cycle. While this can be convenient, it also adds the results of these calculations to the cost of every change detection cycle. This cost has the potential to greatly impact an application’s responsiveness, for example, when binding to a method is combined with an ngFor. There are generally two approaches for improving performance when this happens: pre-computing the results or implementing the method as a pure pipe.
The most common situation in which an ngFor is combined with a method call is to perform a calculation based on each entry that is displayed. Rather than recomputing the display value on every change detection, there is often opportunity to calculate the additional properties as needed. For example consider the following code:
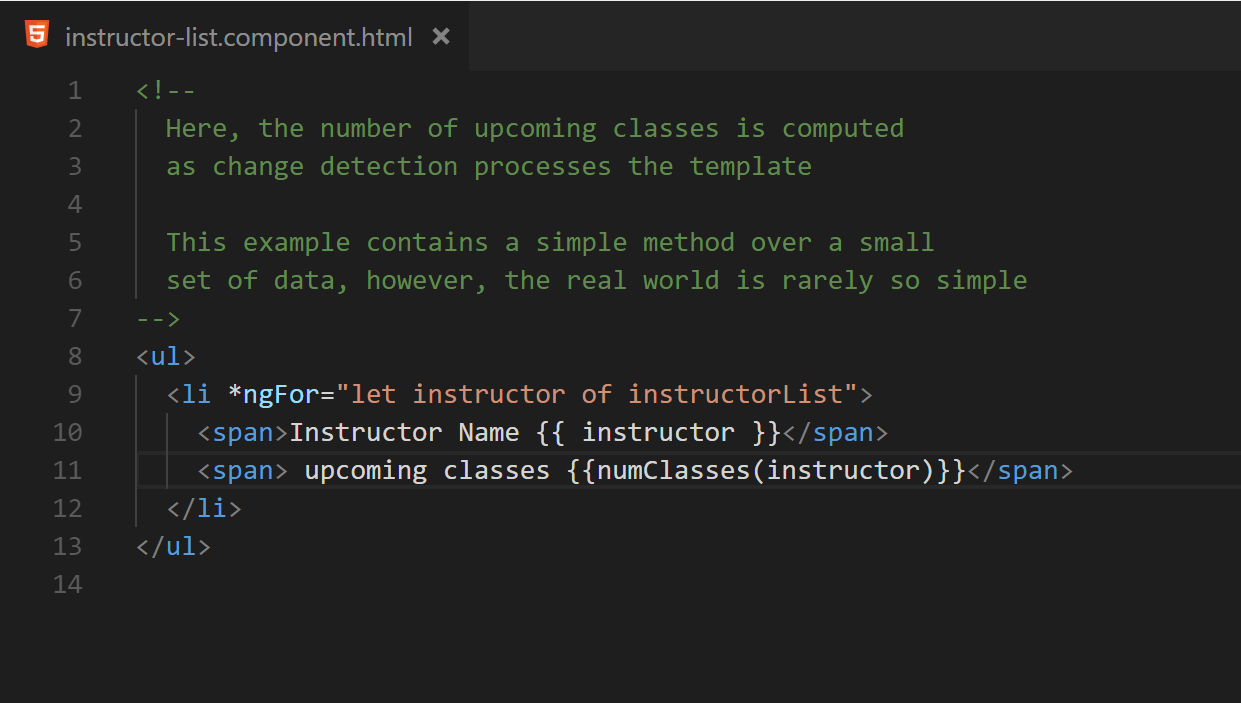
Fig. 19 (Before) A simple template binding that executes numClasses for each entry in instructorList on every change detection cycle
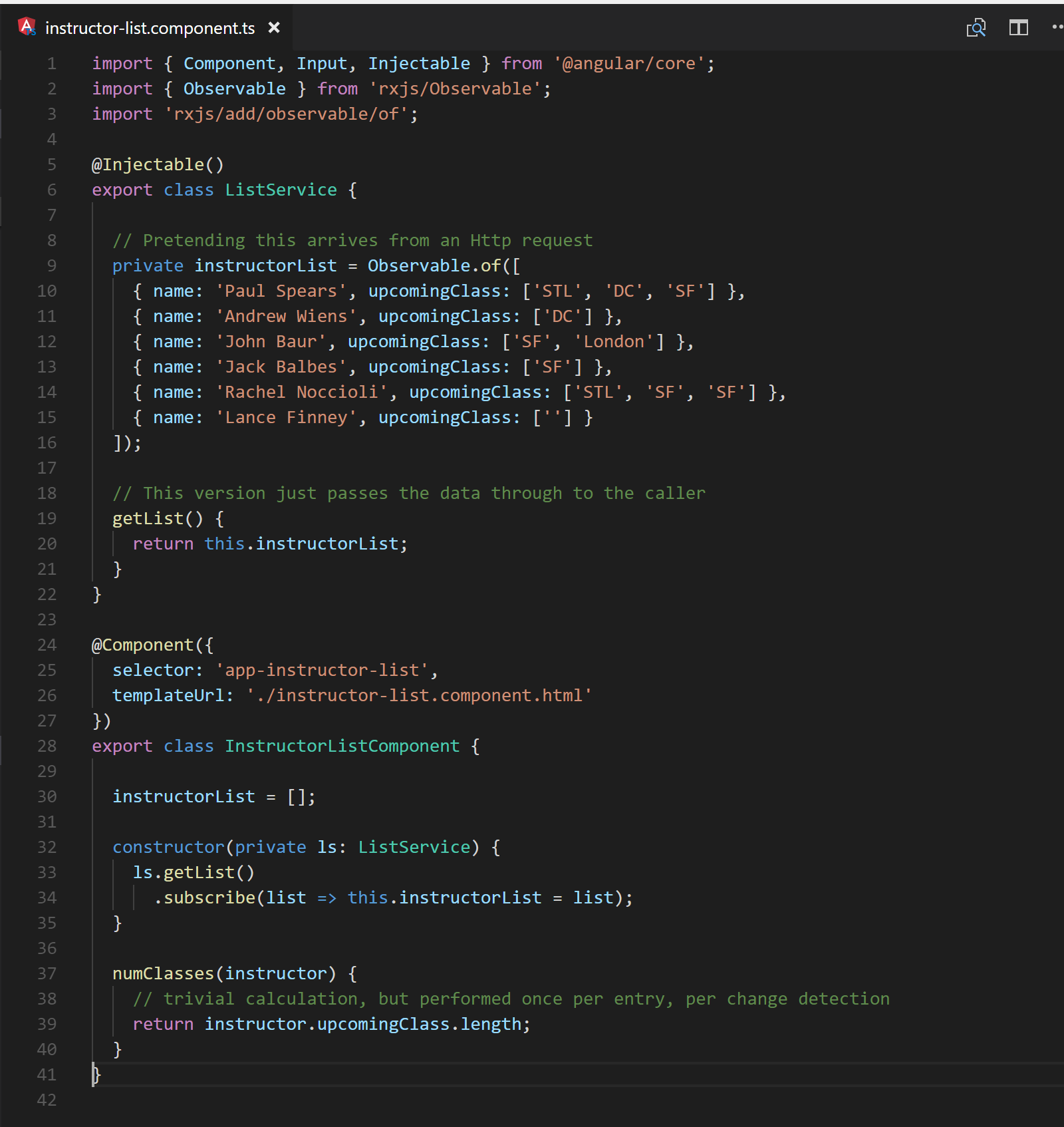
Fig. 20 (Before) The backing component class for the template sources its data with no upfront processing. Line 37 defines the method to call from the template
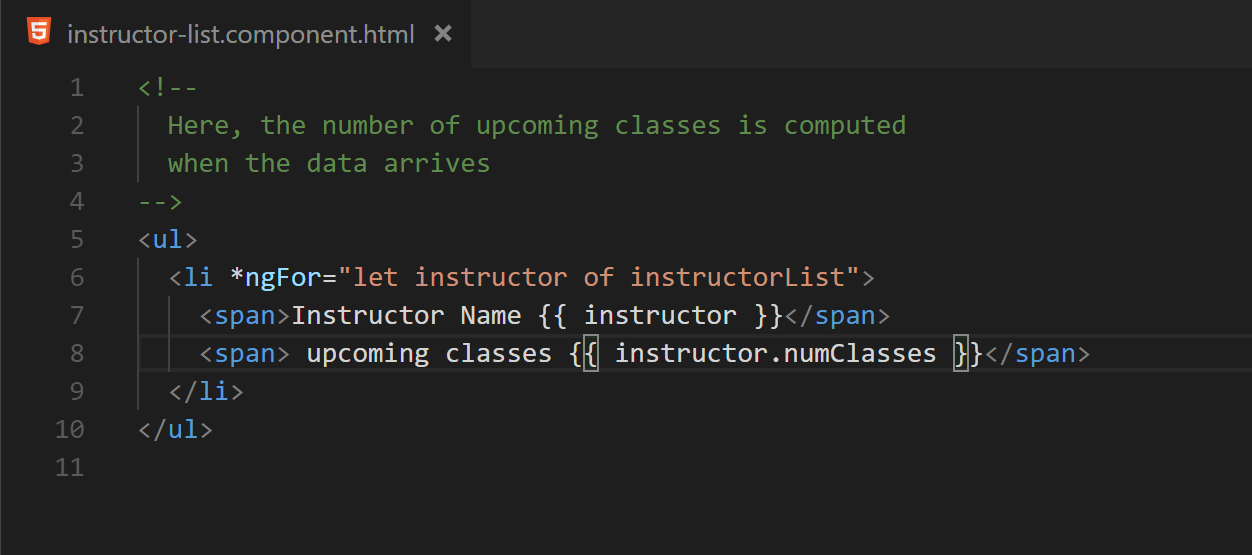
Fig. 21 (After) After some changes in how the instructorList is obtained, there is now a numClasses property that contains the desired value
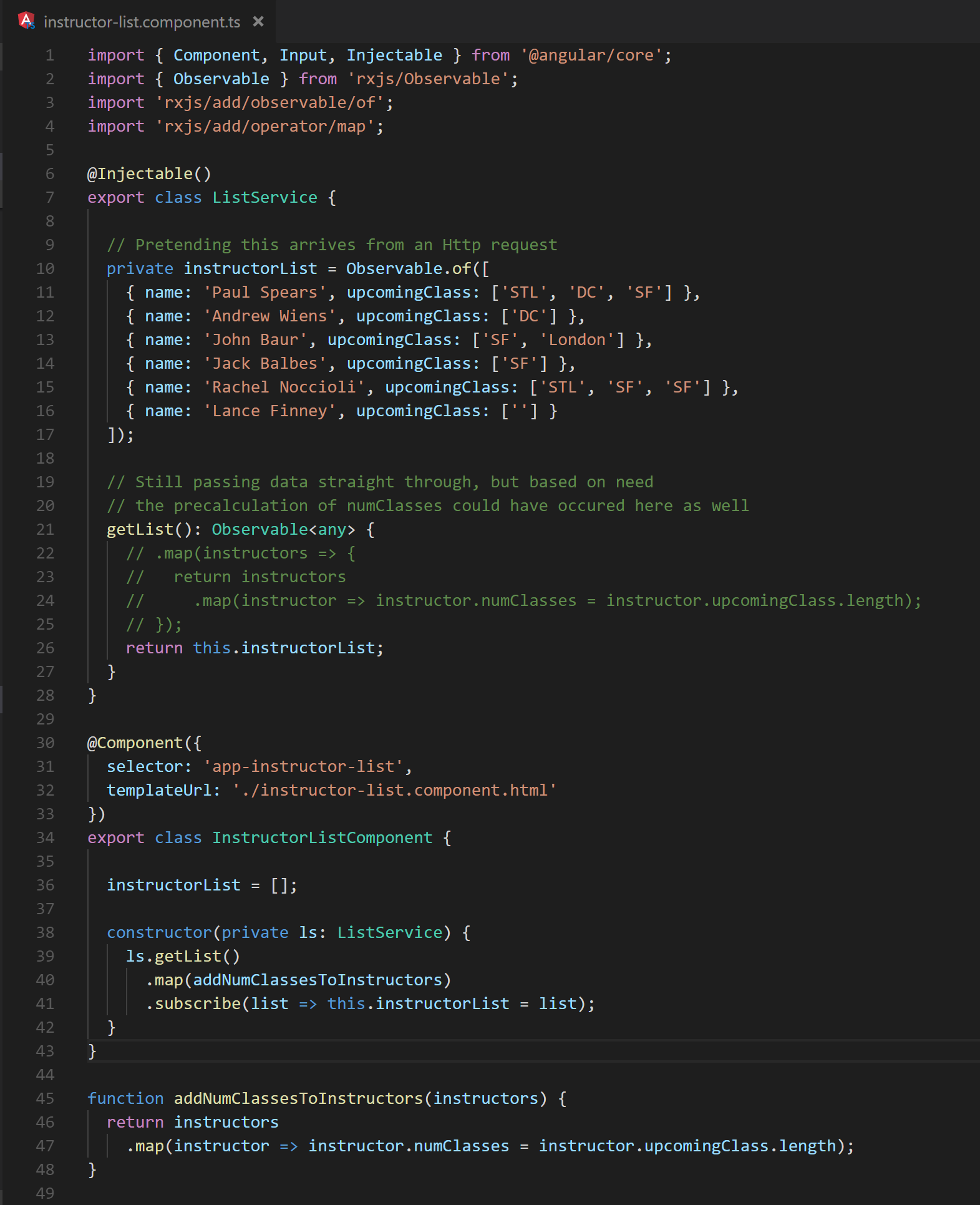
Fig. 22 (After) The backing component class demonstrates how the desired property could be computed upon retrieval and added to the objects.
In this example, object properties are only recalculated if the list changes. This occurs significantly less often than each change detection cycle, possibly never again. This is the most performant way to handle such situations, but it can sometimes be difficult to achieve.
Creating and using a custom pure pipe is generally far more convenient than restructuring the application’s data flow, but it is slightly less performant. A pure pipe is a pipe that behaves much like a pure function: The results of executing it are based solely on its input, and the input is left unchanged. When using a pure pipe in place of method bindings, the pipe is still executed each change detection cycle. However, the execution will benefit from the fact that Angular caches the results of previous executions: If a pipe is executed more than once with the same parameters, the results of the first execution are returned. As a result, although the pipe will still be invoked each change detection cycle in place of the method call, performance will benefit from the caching provided by Angular. Figures 23 and 24 demonstrate the previous example once more with the utilization of a pure pipe.
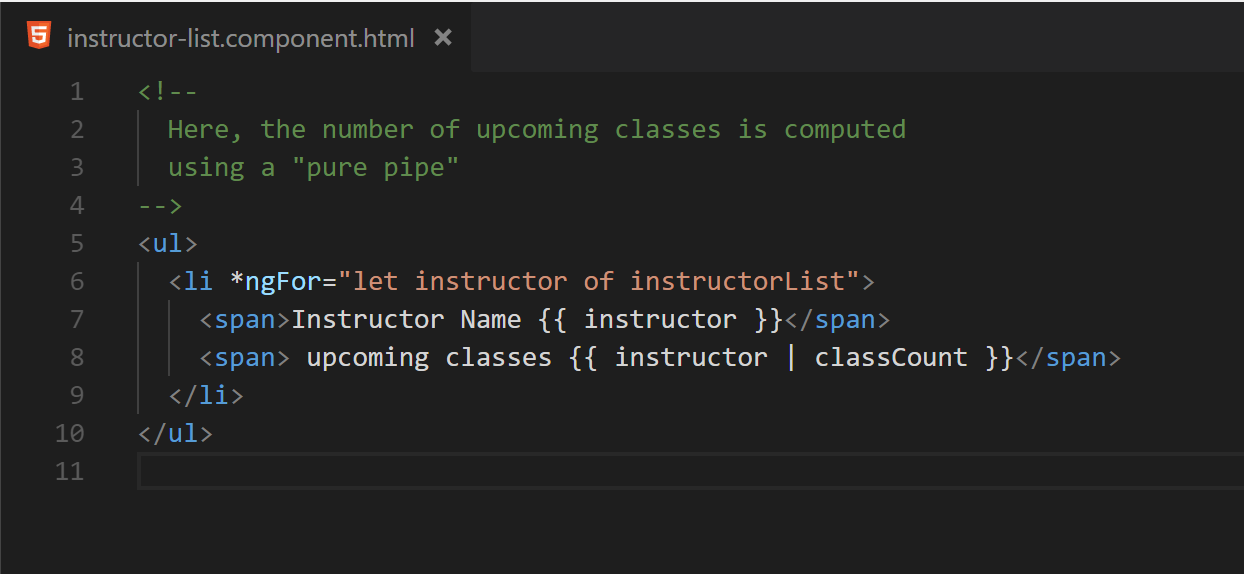
Fig. 23 The template now executes a pipe to produce the desired class count
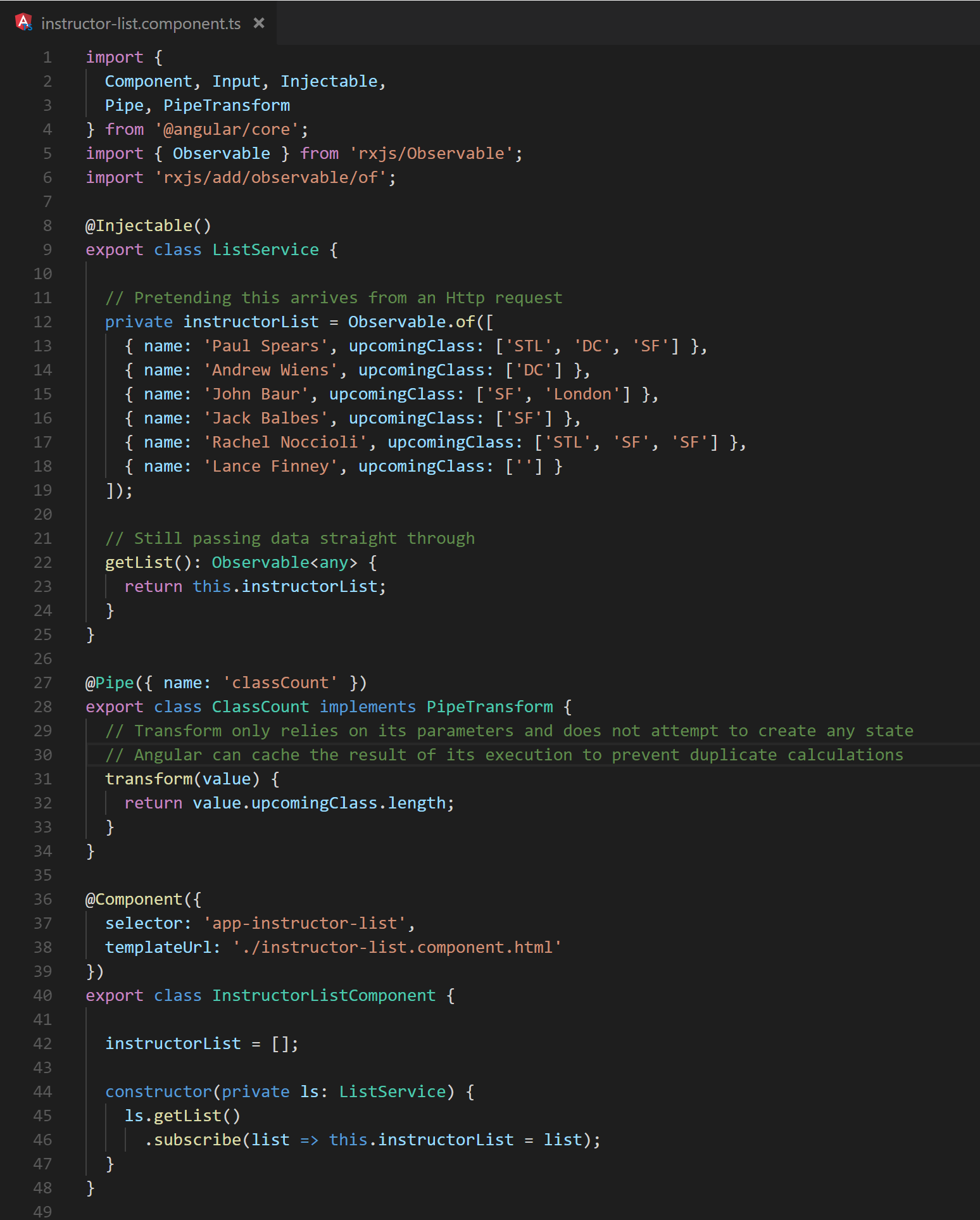
Fig. 24 A custom pipe is introduced, removing the need to precompute the additional data property.
6.2 ngFor
ngFor can also cause excessive DOM manipulation. By default, when iterating over a list of objects, Angular will use object identity to determine if items have been added, removed, or rearranged. This works well for most situations. However, if immutable practices are utilized when updating the data within the list, the identities will be updated and ngFor will generate a new collection of DOM elements to be rendered. If the list is long or complex enough, this will increase the time it takes the browser to render the change. To mitigate this issue, it is possible to use trackBy to tell Angular how to identify the entries as seen in figures 25 and 26.
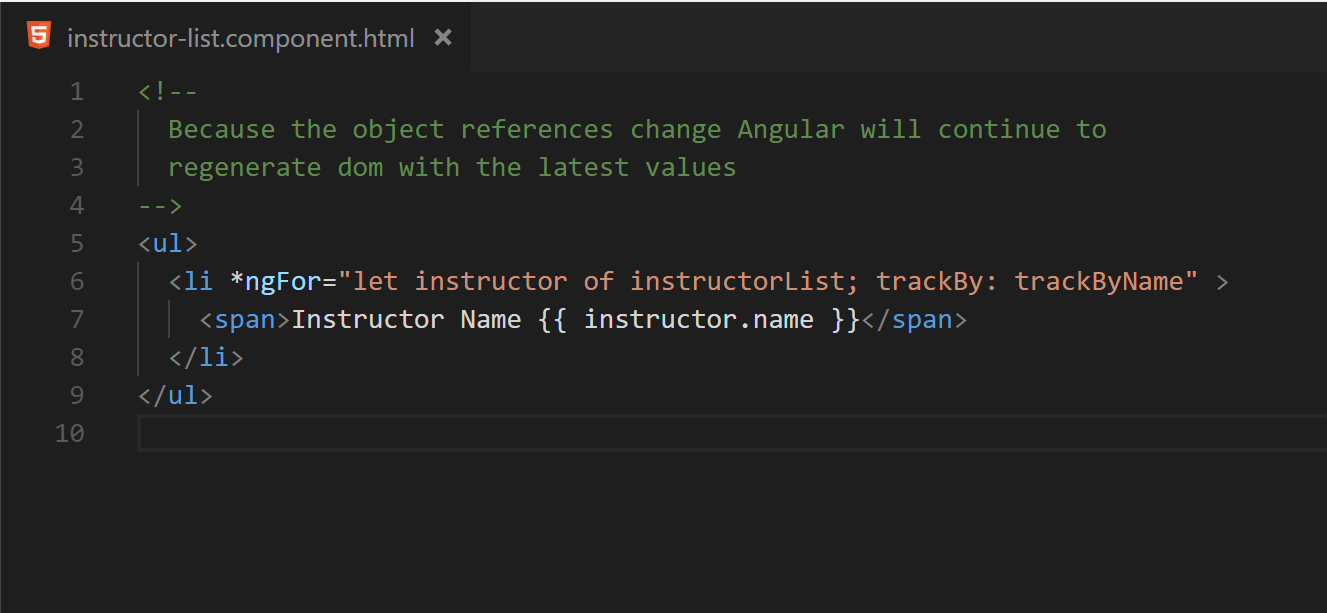
Fig. 25 Expanding a basic ngFor to utilize a trackBy method
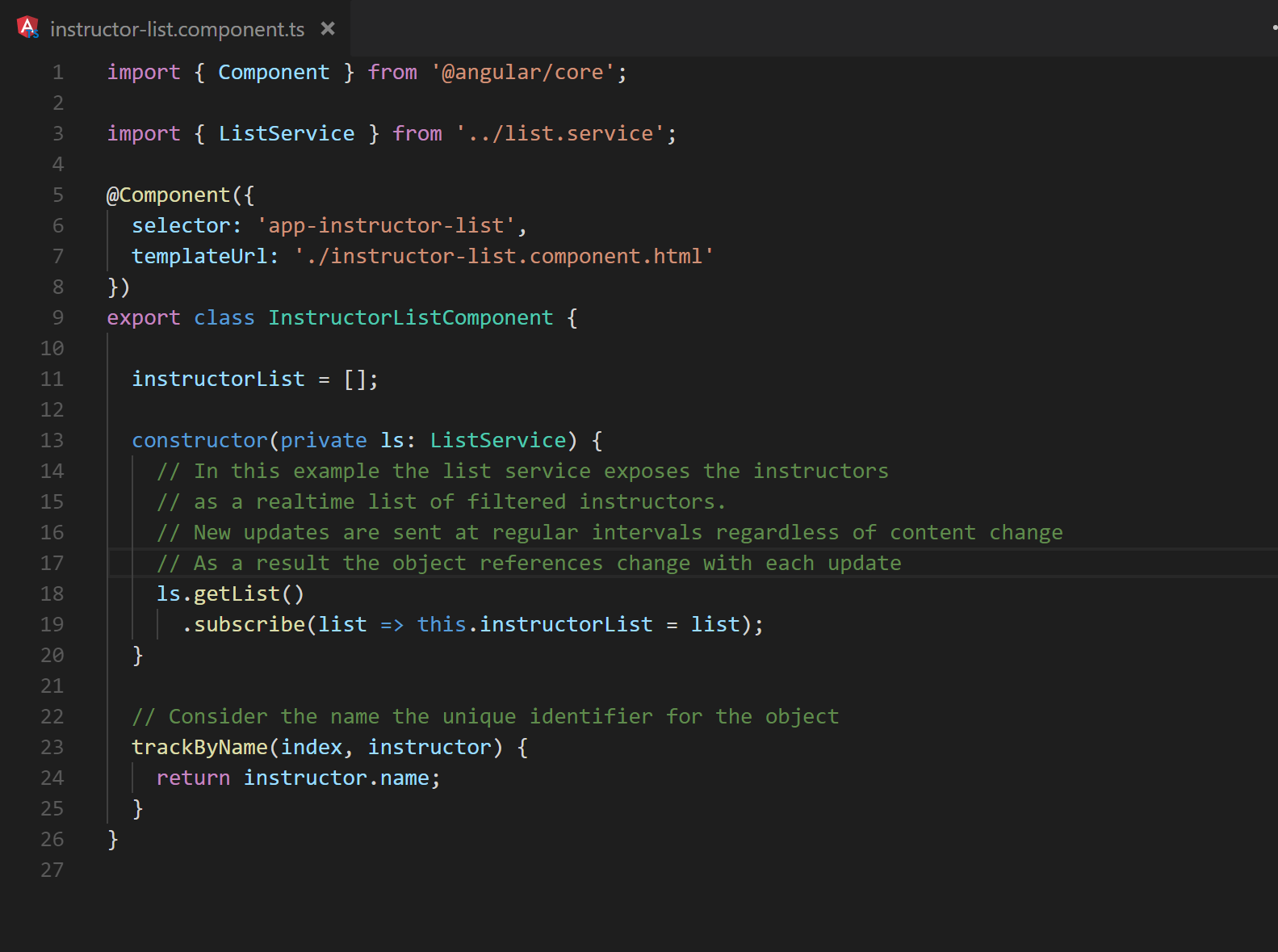
Fig. 26 Line 23 shows the method structure for a trackBy method.
This will reduce the amount of DOM regeneration needed to render any changes even in the case of rapid changes to an immutable data set.
6.3 AOT
The goal of change detection is to translate data changes into a newly-rendered view by updating DOM attributes. Angular runs in just-in-time (JIT) mode by default where its interpretation of component templates is executed as part of the digest cycle. This mode of operation is great when building and debugging an application, but it adds significant overhead in the browser at run time. Compiling Angular using the command line interface (CLI) with both prod mode and ahead-of-time (AOT) compiling reduces this overhead by precompiling the application’s component templates and removing the need for JIT processing.
7.0 Observable Pipelines
Observables are a powerful abstraction for dealing with asynchronous events. Proper usage can result in drastically reduced line counts in an application. However, as a source of change in Angular applications, they should be subject to the same performance scrutiny as component event handlers and change handlers. Observables are closely related to all three of the primary points listed in section 2.0. As such, it is crucial to select the right operators and understand how they are used to ensure that an application’s performance is not degraded by their use.
7.1 distinctUntilChange
When using Observables it is not uncommon that an Observable may emit consecutive duplicates. Depending on the situation it may not be of any benefit to reprocess the same data twice. Rxjs provides an operation, distinctUntilChanged, that will filter any duplicate, consecutive updates from flowing downstream [6]. This operation is shown in Figure 27 as a marble diagram by RxMarbles [7].
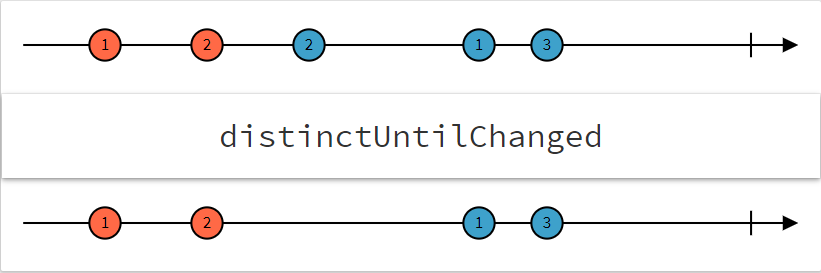
Fig. 27 Marble diagram showing how values pass into and out of distinctUntilChanged
7.2 share
It is quite common in an Angular application to use the data that flows out of an Observable in more than one location. When this happens all of the upstream processing needed to produce the data executes once for each subscription and usage of async pipe. If the callback in the Observable pipeline contain any sufficiently lengthy calculations the cost will add up quickly. Ideally the computation would be executed once for each unique update and the result would be made available to all subscribers. This can be achieved with the observable operator share [8]. Figure 28 utilizes share by sending the result of the Http call into a list display as well as a method used to calculate the total number of classes. In the absence of share, any processing that may be added between lines 12 and 16 of Figure 29 (as well as the Http request!) will be executed for each reference to “results”.
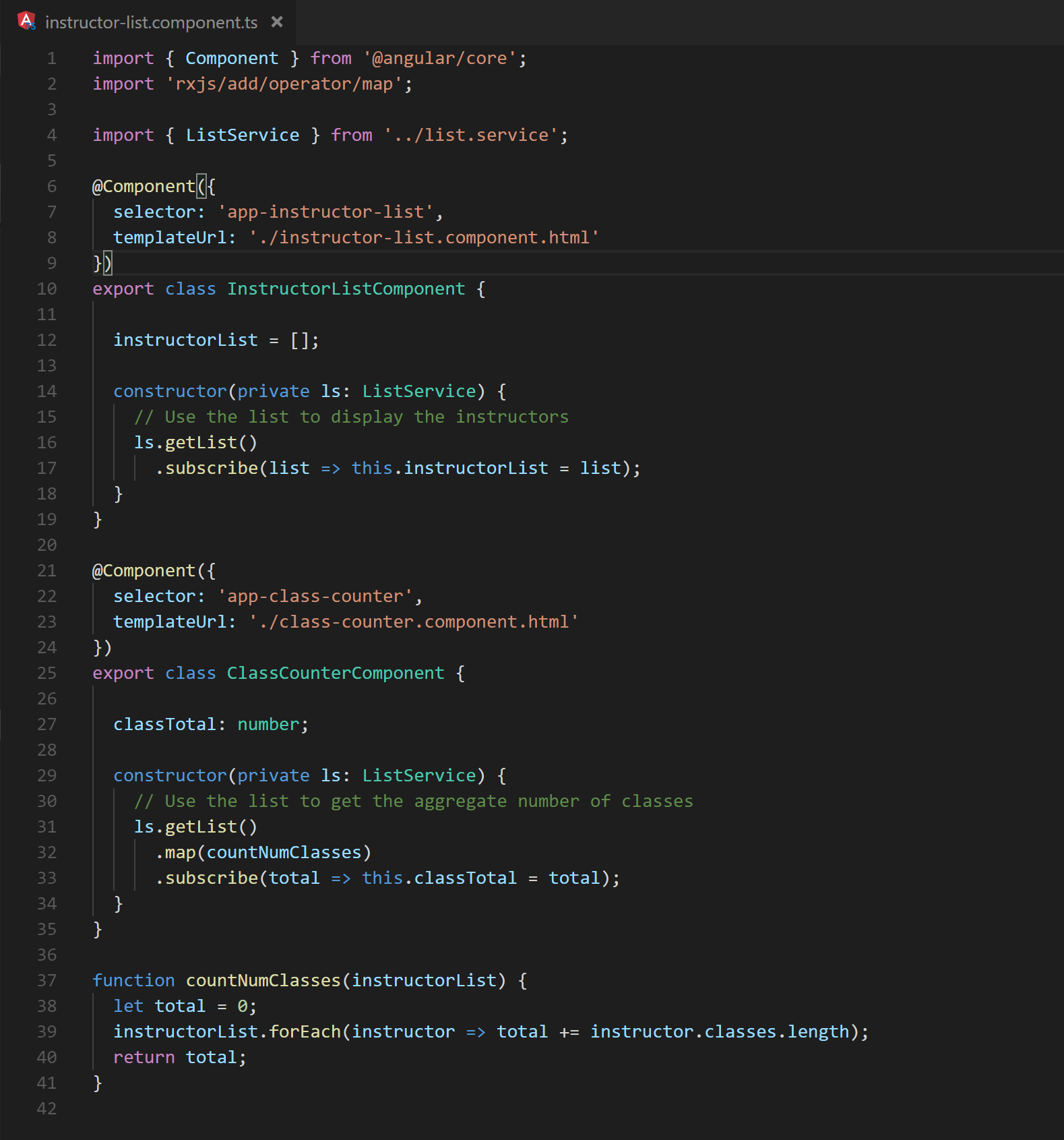
Fig. 28 Lines 16 and 31 demonstrate separate uses of the same Observable data.
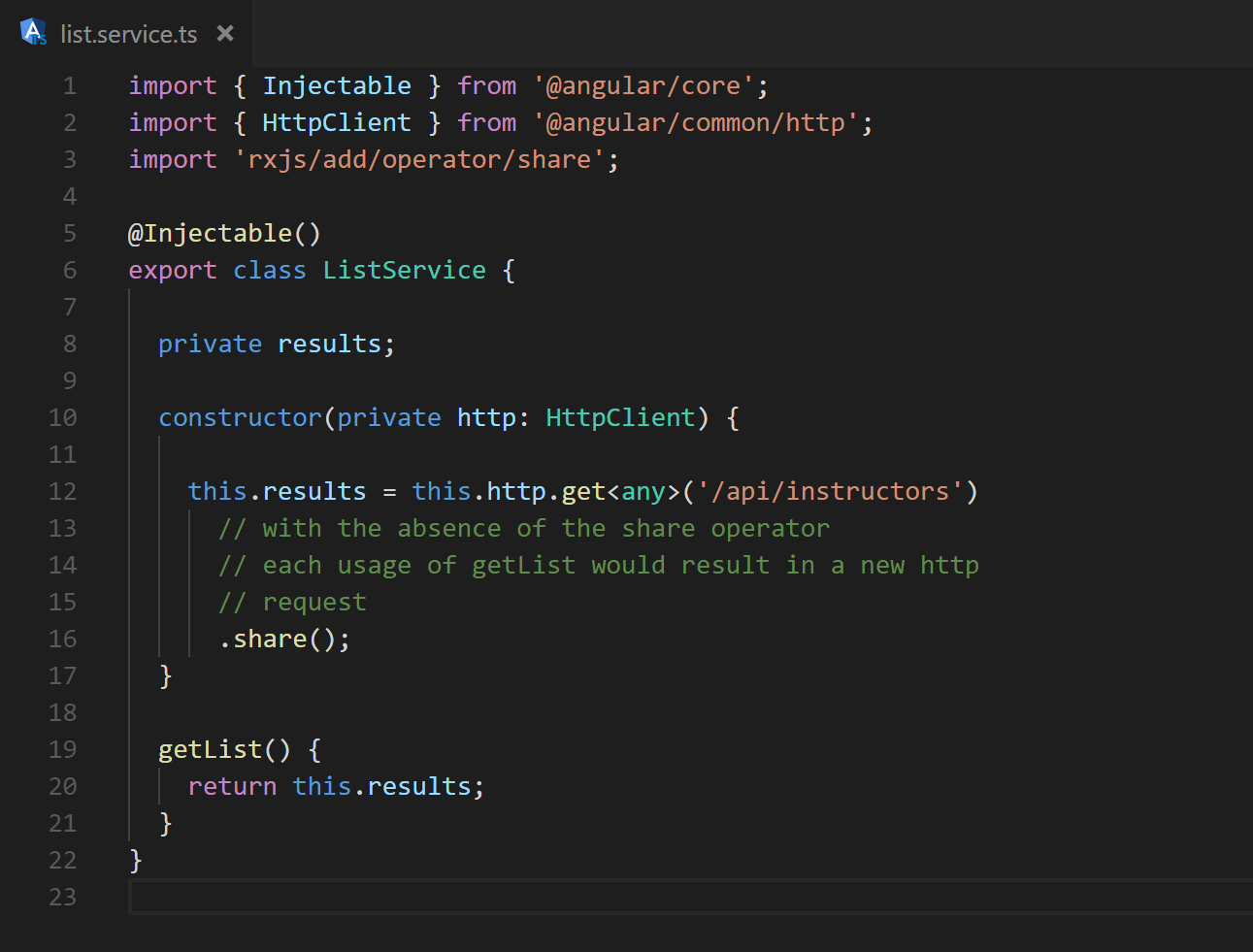
Fig. 29 share is introduced on line 16 to prevent extraneous calculations
7.3 withLatestFrom
Another common use case with Observables is the need to combine multiple streams of data together to calculate some results. This is most often achieved with the usage of the combineLatest operator. As the name implies it is used to combine the latest results from each Observable that is passed in. The callback is passed the results and executed each time any of the supplied observables receive an update. There are situations however, where the calculations need only run when one specific observable changes, but the most recent values of other others are still needed for calculation. In these scenarios it is possible to reduce the number of executions by switching to withLatestFrom [9]. As described above, withLatestFrom will rerun the desired calculation only when the observable it is applied to changes, but makes available the most recent values of all other observables passed as parameters. This operation is shown in Figure 30 as a marble diagram.
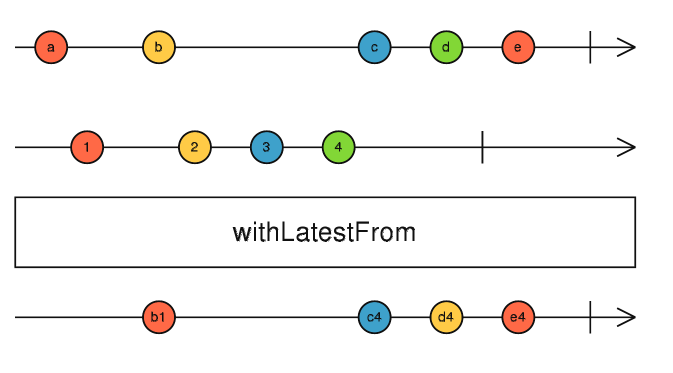
Fig. 30 Marble diagram showing how values pass into and out of withLatestFrom
7.4 throttleTime
Some forms of streaming data occur at a very high frequency. Though it may not be necessary to display each update in the UI. Some use cases only require notifying the user of updates once every n milliseconds. In these situations it may be possible to utilize an operator called throttleTime [10]. This operation is shown in Figure 31 as a marble diagram.
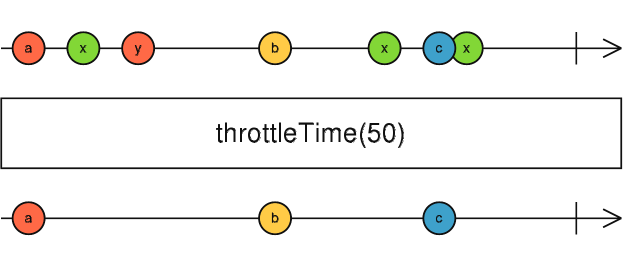
Fig. 31 Marble diagram showing how values pass into and out of throttleTime
8.0 Conclusion
Angular’s change detection system is incredibly quick. However, the ease that Angular affords developers to synchronize custom application functionality to UI updates makes it possible to create unintended performance bottlenecks. Knowing where to look to eliminate these bottlenecks can be difficult. Armed with the performance improvements outlined in this guide, a motivated Angular developer can meet runtime performance needs by designing the application to use Angular’s resources optimally or moving code blocks outside of the Angular layer.
9.0 References
- http://expium.com/visualizer-for-jira
- https://www.angularperformanceplayground.com/app/graph
- https://vsavkin.com/change-detection-in-angular-2-4f216b855d4c
- https://blog.nrwl.io/essential-angular-change-detection-fe0e868dcc00
- https://github.com/dpsthree/angular-performance-playground/blob/master/src/app/d3-helper.service.ts
- http://reactivex.io/rxjs/class/es6/Observable.js~Observable.html#instance-method-distinctUntilChanged
- http://rxmarbles.com/http://reactivex.io/rxjs/class/es6/Observable.js~Observable.html#instance-method-share
- http://reactivex.io/rxjs/class/es6/Observable.js~Observable.html#instance-method-withLatestFrom
- http://reactivex.io/rxjs/class/es6/Observable.js~Observable.html#instance-method-throttleTime



 We can stop enduring the costs and delays of old “float” based CSS layout, and get better results with less work, using CSS Grid – even with Internet Explorer support requirements – with caveats described below.
We can stop enduring the costs and delays of old “float” based CSS layout, and get better results with less work, using CSS Grid – even with Internet Explorer support requirements – with caveats described below.